The hype surrounding the Facebook platform has created a frenzy of hype – on it being a closed wall, on privacy and the right to users having control of their data, and of course the monetisation opportunities of the applications themselves (which on the whole, appear futile but that will change).
We’ve heard of applications becoming targeted, with one (rumoured) for $3 million – and it has proved applications are an excellent way to acquire users and generate leads to your off-Facebook website & products. We’ve also seen applications desperately trying to monetise their products, by putting Google Ads on the homepage of the application, which are probably just as effective as giving a steak to a vegetarian. The other day however was the first instance where I have seen a monetisation strategy by an application that genuinely looked possible.
It’s this application called Compare Friends, where you essentially compare two friends on a question (who’s nicer, who has better hair, who would you rather sleep with…). The aggregate of responses from your friends who have compared you, can indicate how a person sits in a social network. For example, I am most dateable in my network, and one of the people with prettiest eyes (oh shucks guys!).
The other day, I was given an option to access the premium service – which essentially analyses your friends’ responses.

It occurred to me that monetisation strategies for the Facebook platform are possible beyond whacking Google Adsense on the application homepage. Valuable data can be collected by an application, such as what your friends think of you, and that can be turned into a useful service. Like above, they offer to tell you who is most likely to give you a good reference – that could be a useful thing. In the applications current iteration, I have no plans to pay 10 bucks for that data – but it does make you wonder that with time, more sophisticated services can be offered.
Facebook as the bastion of consumer insight
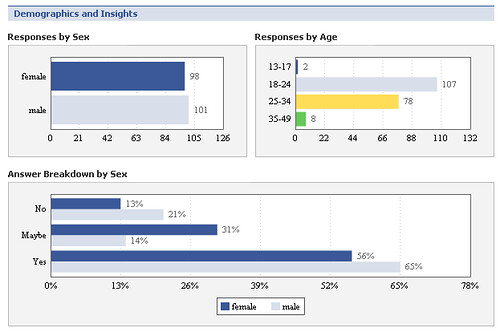
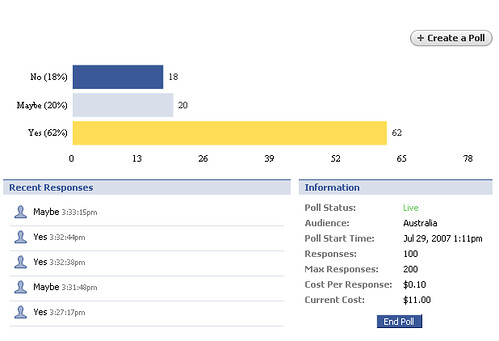
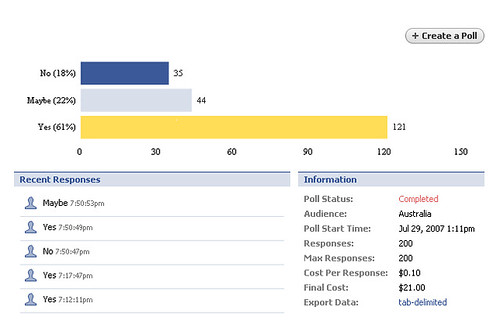
On a similar theme, I did an experiment a few months ago whereby I purchased a facebook poll, asking a certain demographic a serious question. The poll itself revealed some valuable data, as it gave me some more insight into the type of users of Facebook (following up from my original posting). However what it also revealed was the power of tapping into the crowd for a response so quickly.

Seeing the data come in by the minute as up to 200 people took the poll, as a marketer you could quickly gauge how people think about something in a statistically valid sample, in literally hours. You should read this posting discussing what I learned from the poll if you are interested.
It’s difficult to predict the trends I am seeing, and what will become of Facebook because a lot could happen. However one thing is certain, is that right now, it is a highly effective vehicle for individuals to gain insight about themselves – and generating this information is something I think people will pay for if it proves useful. Furthermore, it is an excellent way for organisations to organise quick and effective market research to test a hypothesis.
The power of Facebook, for external entities, is that it gives access to controlled populations whereby valuable data can be gained. As the WSJ notes, the platform has now started to see some clever applications that realise this. Expect a lot more to come.
Facebook is doing what Google did for the industry
When Google listed, a commentator said this could launch a new golden age that would bring optimism not seen since the bubble days to this badly shaken industry. I reflected on that point he made to see if his prophesy would come true one day. In case you hadn’t noticed, he was spot on!
When Google came, it did two big things for the industry
1) AdSense. Companies now had a revenue model – put some Google ads on your website in minutes. It was a cheap, effective advertising network that created an ecosystem. As of 30 June 2007, Google makes about 36% of their revenue from members in the Google network – meaning, non-Google websites. That’s about $2.7 billion. Although we can’t quantify how much their partners received – which could be anything from 20% to 70% (the $2.7 billion of course is Google’s share) – it would be safe to say Google helped the web ecosystem generate an extra $1 billion. That’s a lot of money!
2) Acquisitions. Google’s cash meant that buyouts where an option, rather than IPO, as is what most start-ups aimed for in the bubble days. In fact, I would argue the whole web2.0 strategy for startups is to get acquired by Google. This has encouraged innovation, as all parties from entrepreneurs to VC’s can make money from simply building features rather than actual businesses that have a positive cashflow. This innovation has a cumulative effect, as somewhere along the line, someone discovers an easy way to make money in ways others hadn’t thought possible.
Google’s starting to get stale now – but here comes Facebook to further add to the ecosystem. Their acquisition of a ‘web-operating system‘ built by a guy considered to be the next Bill Gates shows that Facebook’s growth is beyond a one hit wonder. The potential for the company to shake the industry is huge – for example, in advertising alone, they could roll out an advertising network that takes it a step further than contextual advertising as they actually have a full profile of 40 million people. This would make it the most efficient advertising system in the world. They could become the default login and identity system for people – no longer will you need to create an account for that pesky new site asking you to create an account. And as we are seeing currently, they enable a platform the helps other businesses generate business.
I’ve often heard people say that history will repeat itself – usually pointing to how 12 months ago Myspace was all the rage: Facebook is a fad, they will be replaced one day. I don’t think so – Facebook is evolving, and more importantly is that it is improving the entire web ecosystem. Facebook, like Google, is a company that strengthens the web economy. I am probably going to hate them one day, just like how my once loved Google is starting to annoy me now. But thank God it exists – because it’s enabling another generation of commerce that sees the sophistication of the web.