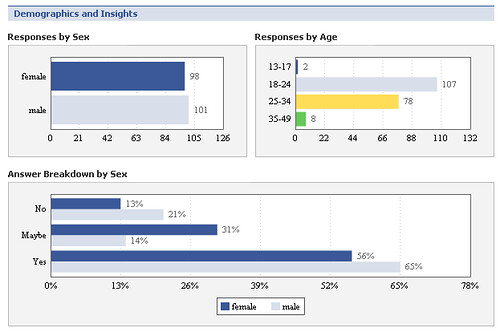
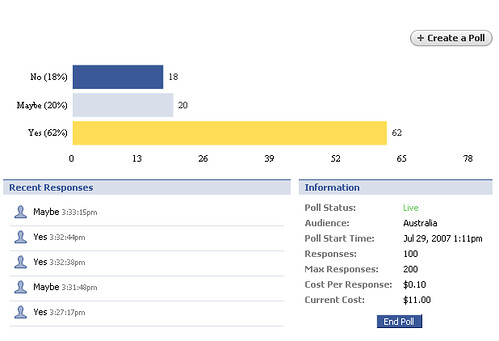
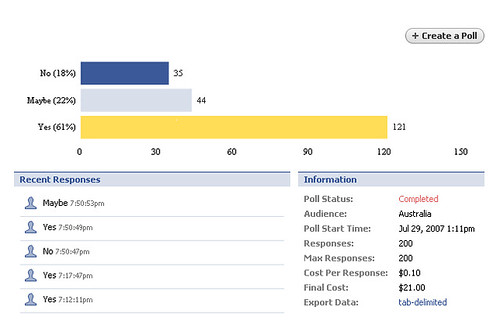
I picked up a book my parents used on their recent trip to Greece, which was a guidebook of the Peloponnese. Flicking through this paper book reminded me of my thoughts of how the content business is so rife with piracy. Especially with an online world now, people can copy content – images, text, audio – and mash it up into their own creation. It seems crazy but why do people enter a business like that?
The Information Sector is not only a big money maker, but very unique as well. Yes, it can be copied and ripped off – unlike a barbie doll where its form can’t really be manipulated into a new product. However different from selling barbies, is that information products do things that are very unique in this world and extremely powerful. In my view there are four types of information product, which can be explained under the categories of data or culture.
Data
New data
A friend and aspiring politician, once said to me that “information is the currency of politics”. Reuters, the famed news organisation that supplies breaking news to media outfits across the world – derives 90% of its revenue from selling up-to-the-minute financial information to stockbrokers and the like who profit on getting information before others. New information, like what the weather will be tomorrow, loses value with time (no many care what the weather was eight days ago). But people are willing to pay a price, and a big one, to get access to this breaking news because it can help make decisions.
Old data
On the flip side, old information can be very valuable because of the ability to conduct research and analysis. Search engines effectively fit into this segment of the information economy, because they can query past news and knowledge to produce answers. Extending the weather example, being about to find out that data eight days ago along with the weather exactly one, five and ten years ago – can help you identify trends that, for example, validates the global warming theory.
Culture
Analysis
The third category of information products, I call them simply analysis because what they are is unique insight into things. We all have access to the same news for example, but it takes a smart thinker to create a prediction, by pulling the pieces together and creating new value from them. Analytical content usually gets plagiarised by students writing essays, but its also the stuff that shapes peoples perceptions in world-changing ways.
Entertainment
One of the most powerful uses of content is the way it can impact people – entertainment type content is the stuff that generates emotion in people. Emotions are a key human trait that you should keep in mind in any decision – no matter how logical someone is, the emotional self can overtake. A documentary that portrays an issue negatively, and that can generate an angry response in a person, is the stuff that can topple governments and corporations.
Not all information is equal
If you are a content creator, you need to accept that other people can copy your creation. The key is to understand what type of content you are creating, and develop a content strategy that exploits its unique characteristics.
Information products need different strategies in order to effectively monetise them. Below is a brief discussion which extends on the above to help you understand.
New data
With this type of content, the value is in the time; the quicker that information can be accessed, the more useful it is. News items (like current affairs) fit into this category. As a news consumer, I don’t care how I get my news, but I care about how quickly I can get it. It’s for this reason I no longer read newspapers, yet through various technologies like RSS and my mobile phone, that I probably consume more news than ever before.
You should sell this data based on access – the more you pay, the quicker the access. Likewise, the ability to enable multiple outputs is key – you need to be able to deliver your content to as many different places as possible: SMS, email, RSS etc. You should not discriminate on the output; the value is on the time.
If you create news breaks, why are you wasting your time on who can access that information, because of the threat that someone can copy it? If the value is in the time, who cares who copies it because by the time they republish it, its already lost value. A flash driven site like the Australian Financial Review is an example of a management that doesn’t realise this.
Old data
A recent example of action in this space is the New York Times who have recently removed their paid subscription wall, which was previously only available via subscription but now can be accessed by anyone for free. This is a smart business move, because if you are selling archived content, you will make more money by having more people know what exists. A paid wall limits people using it which decreases the opportunity for consumption: you a relying on a brand only to create demand. If you are website with a lot of historical content – restricting access is stupid because you are effectively asking people to pay for access to something that they have no idea what value it holds for them. It’s a bit like traveling – if you’ve never been overseas, you don’t know what you are missing out on. Give people a taste of the travel bug, and they will never be able to sit still.
Unlike new data where the value is based on time, old data finds value on accessibility. People will place value on things like search, and the ability to find relevant content through the mountains of content available. Here the multitude of outputs doesn’t matter, because researchers have all the time in the world. What matters is a good interface, and powerful tools to mine the data: the value is on being to find information. You shouldn’t charge people on access to the content; where you will make money is on the tools to mine the data.
Analysis
This type of content is difficult to create, but easily ripped off by other people – just think of how rife plagiarism is with schools and universities, where the latter treats plagiarism as a crime just short of murder. You can distinguish this type of content as it demonstrates the ability to offer content that is was produced from a common set on inputs that anyone could access, and creating a viewpoint that only a certain type of person could create. The value is on the unique insight.
Despite the higher intlellect to product, it unfortunately is content that is harder to capitalise on. A lot of technology blogs feel the pressure of moving into a more news style than analytical service because news is what gets eyeballs. If you are a blogger looking to make money – the new data approach above should be your strategy. But if you are a blogger trying to build your brand – do analysis. The consequence with analysis is that its harder to do, so you shouldn’t feel pressured to produce more content. I’ve noticed a trend for example, that if I post more blog postings, I will get more traffic. But on the same token, more postings puts more pressure on me, which means less quality content. Understand that the value of analysis isn’t dependent on time. Or better said, the value of analysis is not how quickly it gets pumped out and realised, but how thoroughly it gets incubated as an idea and later communicated.
The value for analysis is clarity and ability to offer new thoughts. To look at the relationship with advertising models, new data like news (discussed above) typically gets higher viewers – which works for the pageview model (the more people refreshing, the more CPMs). Analysis, on the other hand, works with the time spent model. Take advantage of the engagement you have with those types of readers, because you are cultivating a community of smart people – there can be a lot more loyalty with that type of readership.
Entertainment
My sister downloads the Chaser’s War on Everything as a podcast. She first came across them on the radio, but she now downloads the podcasts religiously. Even though I knew about the Chaser’s efforts for years in their various products, I didn’t realise they were still around. If the last few weeks, I have been noticing my friends bring up the shows they are doing. The value in this content was the ability to make people laugh, due to their unique stunts. Their brand is built because of word of mouth recommendations.
Like analysis, entertainment can be a very hard thing to generate because it relies on unique thinking. With a strong brand, people will pay for access to that content. Although it may seem that the viral spreading of funny content for free is a nightmare for a content producer trying to collect royalties, it’s actually a good thing because it entrenches the brand: more people will find out about it. The nature of entertainment, like analysis, is that it is difficult to do repeatedly. Sure people can copy your individual tricks – but they can only do so after the fact. They can’t pre-anticipate the next thing you will do; because unlike breaking news which is on how quickly you can pump out content, entertainment content requires a unique creative process to produce it.
The key with entertainment content, is to build a relationship with an audience and to sustain it. Create a predictable flow of content. Encourage people copying it, because all it does it get more people wanting to see what you come up with next. If it wasn’t for Stephen Colbert‘s clips on Youtube, I would never have realised his brilliance. Not knowing he existed, means a DVD set of his shows means nothing to me (but which holds a lot of value now). The value of entertainment is to generate emotions in people repeatedly. Emotions are a powerful influence on human behaviour – master that and you can be dangerous!
Concluding thoughts
This posting only touches on the issues, but what I suggest is that creators of content need to look at what type of content they are producing, for them to exploit its unique aspects. Content represents human ideas, and content isn’t distiguished by a physical form. The theft of your content should be a given and can actually help you. Depending on what that content is, there may be natural safeguards that make it irrelevant (ie, the time value of news).