I’ve been quoted in RWW and other places as saying the following:
“Users should have the ability to decide upfront what data they permit, not after the handshake has been made where both Facebook and the app developer take advantage of the fact most users don’t know how to manage application privacy or revoke individual permissions,” Bizannes told the website. “Data Portability is about privacy-respecting interoperability and Facebook has failed in this regard.”
Let me explain what I mean by that:
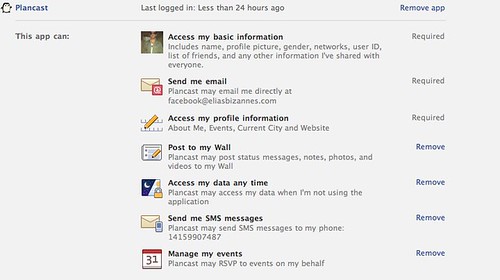
This first screenshot is what users can do with applications. Facebook offers you the ability to manage your privacy, where you even have the ability to revoke individual data authorisations that are not considered necessary. Not as granular as I’d like it (my “basic information” is not something I share equally with “everyone”, such as apps who can show that data outside of Facebook where “everyone” actually is “everyone”), but it’s a nice start.
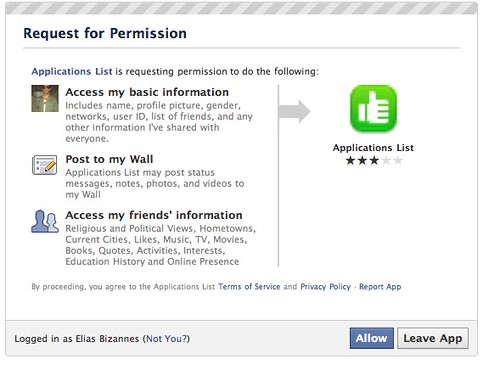
This second screenshot, is what it looks like when you initiate the relationship with the application. Again, it’s great because of the disclosure and communicates a lot very simply.
But what the problem is, is that the first screenshot should be what you see in place of the second screenshot. While Facebook is giving you the ability to manage your privacy, it is actually paying lipservice to it. Not many people are aware that they can manage their application privacy, as it’s buried in a part of the site people seldom use.
The reason why Facebook doesn’t offer this ability upfront is for a very simple reason: people wouldn’t accept apps. When given a yes or no option, users think “screw it” and hit yes. But what if they did this handshake, they were able to tick off what data they allowed or didn’t allow? Why are all these permissions required upfront, when I can later deactivate certain permissions?
Don’t worry, its not that hard to answer. User privacy doesn’t help with revenue revenue growth in as much as application growth which creates engagement. Being a company, I can’t blame Facebook for pursuing this approach. But I do blame them when they pay lipservice to the world and they rightfully should be called out for it.
Mike Melanson interviewed me today over the whole Facebook vs Google standoff. He wrote a nice piece that I recommend you read, but I thought I would expand on what I was quoted on to give my full perspective.
To me, there is a bigger picture battle here, and it’s for us to see true data interoperability on the Internet, of which this is but a minor battle in the bigger war.
I see a strong parallel to global trade and data portability on the web. Like in the days of restrictive trade tariffs that have been progressively demolished with globalisation, the ‘protectionism’ being cried out by each party of protecting their users is but a hollow attempt to satisfy their voters in the short-term, which are the shareholders of each company. This tit-for-tat approach is what governments still practice with trade and people-travel restrictions, but which at the end of the day hurts individuals in the short-term but society as a whole in the longer term. It doesn’t help anyone but give companies (and as we’ve seen historically, governments) a short term sigh of relief.
You only have to look at Australia, which went from having some of the highest trade tariffs in the world in the ’70s to being one of the most open economies in the world by the ’90s. The effect of this is that it made it one of the most competitive economies in the world, which is part of the reason that of all the OECD countries during the recent financial crisis, it managed to be the only economy not to fall into recession. Companies, like the economies governments try to protect, need to be able to react to their market to survive, and they can only do that successfully in the long term by being truly competitive.
The reality is, Facebook and Google are hurting the global information network, as true value unlocks when we have a peered privacy-respecting interoperability network. The belief that value is interpreted as who holds the most data, is a mere attempt to buy time for their true competitive threat — the broader battle for interoperability — which will expose them to compete not on the data they acquired but on their core value as a web service to use that data. These companies need to recognise what their true comparative advantage is and what they can do with that data.
Google and Facebook have improved a lot over the years with regards to data portability, but they continue to make the mistake (if not in words, but in actions) — that locking in the data is the value. Personal information acquired by companies loses value with time — people’s jobs, locations, and even email accounts — change over time and are no longer relevant. What a site really wants is persistent access to a person so they can tap into the more recently updated data, for whatever they need. What Google and Facebook are doing is really hurting them as they would benefit by working together. Having a uniform way of transferring data between their information network silo’s ensures privacy-respecting ways that minimise the risk for the consumer (which they claim to be protecting) and the liberalisation of the data economy means they can in the long term focus on their comparative advantage with the same data.
Application Programming Interfaces – better known in the technology industry as API’s – have come out as one of the most significant innovations in information technology. What at first appears a geeky technical technique for developers to play with, is now evolving into something that will underpin our very society (assuming you accept information has, is, and will be the the crux of our society). This post explores the API and what it means for business.
What is it?
In very simple terms, an API is a set of instructions a service declares, that outsiders can use to interact with it. Google Maps has one of the most popular API’s on the Internet and provides a good example of their power. Google hosts terabytes of data relating to its mapping technology, and it allows developers not affiliated with Google to build applications on top of Google’s. For example, thousands of websites like the NYTimes.com have integrated Google’s technology to enhance their own.
An example more familiar with ordinary consumers would be Facebook applications. Facebook allows developers through an API to create ‘apps’ that have become one of the main sources of entertainment on Facebook, the world’s most popular social networking site. Facebook’s API determines how developers can build apps that interact with Facebook and what commands they need to specify in order to pull out people’s data stored in Facebook. It’s a bit like a McDonald’s franchise – you are allowed to use McDonald’s branding, equipment and supplies, so long as you follow the rules in being a franchisee.
API’s have become the centre of the mashup culture permeating the web. Different websites can interact with each other – using each others technology and data – to create innovative products.
What incentive do companies have in releasing an API?
That’s the interesting question that I want to explore here. It’s still early days in the world of API’s, and a lot of companies seem to offer them for free – which seems counter-intuitive. But on closer inspection, it might not. Free or not, web businesses can create opportunity.
Free doesn’t mean losing
An API that’s free has the ability to generate real economic value for a new web service. For example, Search Engine Optimisation (SEO) has become a very real factor in business success now. Becoming the top result for the major search engines generates free marketing for new and established businesses.
In order for companies to boost their SEO rankings, one of the things they need to do is have a lot of other websites pointing links at them. And therein flags the value of an open API. By allowing other people to interact with your service and requiring some sort of attribution, it enables a business to boost their SEO dramatically.
Scarcity is how you generate value
One of the fundamental laws of economics, is that to create value, you need something to be scarce. (That’s why cash is tightly controlled by governments.) Twitter, the world’s most popular micro-blogging service, is famous for the applications that have been built on their API (with over 11,000 apps registered). And earlier this year, they really got some people’s knickers in a knot when they decided to limit usage of the API.
Which is my eyes was sheer brilliance by the team at Twitter.
By making their API free, they’ve had hundreds of businesses build on top of it. Once popular, they could never just shut the API off and start charging access for it – but by introducing some scarcity, they’ve done two very important things: they are managing expectations for the future ability to charge additional access to the API and secondly, they are creating the ability to generate a market.
The first point is better known in the industry as the Freemium model. Its become one of the most popular and innovative revenue models in the last decade on the Internet. One where it’s free for people to use a service, but they need to pay for the premium features. Companies get you hooked on the free stuff, and then make you want the upgrade.
The second point I raised about Twitter creating a market, is because they created an opportunity similar to the mass media approach. If an application dependent on the API needs better access to the data, they will need to pay for that access. Or why not pay someone else for the results they want?
Imagine several Twitter applications that every day calculate a metric – that eats their daily quota like no tomorrow – but given it’s a repetitive standard task, doesn’t require everyone having to do it. If the one application of say a dozen could generate the results, they could then sell it to the other 11 companies that want the same output. Or perhaps, Twitter could monitor applications generating the same requests and sell the results in bulk.
That’s the mass media model: write once, distribute to many. And sure, developers can use up their credits within the limit…or they can instead pay $x per day to get the equivalent information pre-mapped out. By limiting the API, you create an economy based on requests (where value comes through scarcity) – either pay a premium API which gives high-end shops more flexibility or pay for shortcuts to pre-generated information.
With reference to my model, the API offers the ability for a company to specialise at one stage of the value chain. The processing of data can be a very intensive task, and require computational resources or raw human effort (like a librarian’s taxonomy skills). Once this data is processed, a company can sell that output to other companies, who will generate information and knowledge that they in turn can sell.
I think this is one of the most promising opportunities for the newspaper industry. The New York Times last year announced a set of API’s (their first one being campaign finance data), that allows people to access data about a variety of issues. Developers can then query this API, and generate unique information. It’s an interesting move, because it’s the computer scientists that might have found a future career path for journalists.
Journalists skills in accessing sources, determining significance of information, and conveying it effectively is being threatened with the democratisation of information that’s occurred due to the Internet. But what the NY Times API reflects, is a new way of creating value – and it’s taking more of a librarian approach. Rather than journalism become story-centric, their future may be one where it is data based, which is a lot more exciting than it sounds. Journalists yesterday were the custodians of information, and they can evolve that role to one of data instead. (Different data objects connected together, by definition, is what creates information.)
A private version of the semantic web and a solution for data portability
The semantic web is a vision by the inventor of the World Wide Web, which if fully implemented, will make the advances of the Internet today look like prehistory. (I’ve written about the semantic web before to give those new to the subject or skeptical.) But for those that do know of it, you probably are aware of one problem and less aware of another.
The obvious problem is that it’s taking a hell of a long time to see the semantic web happen. The not so obvious problem, is that it’s pushing for all data and information to be public. The advocacy of open data has merit, but by constantly pushing this line, it gives no incentive for companies to participate. Certainly, in the world of data portability, the issue of public availability of your identity information is scary stuff for consumers.
Enter the API.
API’s offer the ability for companies to release data they have generated in a controlled way. It can create interoperability between different services in the same way the semantic web vision ultimately wants things to be, but because it’s controlled, can overcome this barrier that all data needs to be open and freely accessible.
Concluding thoughts
This post only touches on the subject. But it hopefully makes you realise the opportunities created by this technology advance. It can help create value without needing to outlay cash; new monetisation opportunities for business; additional value in society due to specialisation; and the ability to bootstrap the more significant trends in the Web’s evolution.
In the half century since the Internet was created – and the 20 years that the web was invented – a lot has changed. More recently, we’ve seen the Dot Com bubble and the web2.0 craze drive new innovations forward. But as I’ve postulated before, those eras are now over. So what’s next?
Well, ubiquity of course.
Huh?
Let’s work backwards with some questions to help you understand.
Why do we now need ubiquity, and what exactly that means, requires us to think of another two questions. The changes brought by the Internet are not one big hit, but a gradual evolution. For example, “Open” has existed since the first days of the Internet in culture: it wasn’t a web2.0 invention. But “openess” was recognised by the masses only in web2.0 as a new way of doing things. This “open” culture had profound consequences: it led to the mass socialisation around content, and recognition of the power that is social media.
As the Internet’s permeation in our society continues, it will generate externalities that affect us (and that are not predictable). But the core trend can be identifiable, which is what I hope to explain in this post. And by understanding this core trend, we can comfortably understand where things are heading.
So let’s look at these two questions:
1) What is the longer term trend, that things like “open” are a part of?
2) What are aspects of this trend yet to be fully developed?
The longer term trend
The explanation can be found into why the Internet and the web were created in the first place. The short answer: interoperability and connectivity. The long answer – keep reading.
Without going deep into the history, the reason why the Internet was created was so that it could connect computers. Computers were machines that enabled better computation (hence the name). As they had better storage and querying capacities than humans, they became the way the US government (and large corporations) would store information. Clusters of these computers would be created (called networks) – and the ARPANET was built as a way of building connections between these computers and networks by the US government. More specifically, in the event of a nuclear war and if one of these computing networks were eliminated – the decentralised design of the Internet would allow the US defense network to rebound easily (an important design decision to remember).
The web has a related but slightly different reason for its creation. Hypertext was conceptualised in the 1960s by a philosopher and scientist, as a way of harnessing computers to better connect human knowledge. These men were partly inspired by an essay written in the the 1940s called “As We May Think“, where the chief scientist of the United States stated his vision whereby all knowledge could be stored on neatly categorised microfirm (the information storage technology at the time), and in moments, any knowledge could be retrieved. Several decades of experimentation in hypertext occurred, and finally a renegade scientist created the World Wide Web. He broke some of the conventions of what the ideal hypertext system would look like, and created a functional system that solved his problem. That being, connecting all these distributed scientists around the world and their knowledge.
So as it is clearly evident, computers have been used as a way of storing and manipulating information. The Internet was invented to connect computing systems around the world; and the Web did the same thing for the people who used this network. Two parallel innovative technologies (Internet and hypertext) used a common modern marvel (the computer) to connect the communication and information sharing abilities of machines and humans alike. With machines and the information they process, it’s called interoperability. With humans, it’s called being connected.
But before we move on, it’s worth noting that the inventor of the Web has now spent a decade advocating for his complete vision: a semantic web. What’s that? Well if we consider the Web as the sum of human knowledge accessible by humans, the Semantic Web is about allowing computers to be able to understand what the humans are reading. Not quite a Terminator scenario, but so computers can become even more useful for humans (as currently, computers are completely dependent on humans for interpretation).
What aspects of the trend haven’t happened yet?
Borders have been broken down that previously restrained us. The Internet and Hyptertext are enabling connectivity with humans and interoperability for computer systems that store information. Computers in turn, are enabling humans to process tasks that could not be done before. If the longer term trend is connecting and bridging systems, then the demon to be demolished are the borders that create division.
So with that in mind, we can now ask another question: “what borders exist that need to be broken down?” What it all comes down to is “access”. Or more specifically, access to data, access to connectivity, and access to computing. Which brings us back to the word ubiquity: we now need to strive to bridge the gap in those three domains and make them omnipresent. Information accessible from anywhere, by anyone.
Let’s now look at this in a bit more detail
– Ubiquitous data: We need a world where data can travel without borders. We need to unlock all the data in our world, and have it accessible by all where possible. Connecting data is how we create information: the more data at our hands, the more information we can generate. Data needs to break free – detached from the published form and atomised for reuse.
– Ubiquitous connectivity: If the Internet is a global network that connects the world, we need to ensure we can connect to that network irregardless of where we are. The value of our interconnected world can only achieve its optimum if we can connect wherever with whatever. At home on your laptop, at work on your desktop, on the streets with your mobile phone. No matter where you are, you should be able to connect to the Internet.
– Ubiquitous computing: Computers need to become a direct tool available for our mind to use. They need to become an extension of ourselves, as a “sixth sense”. The border that prevents this, is the non-assimilation of computing into our lives (and bodies!). Information processing needs to become thoroughly integrated into everyday objects and activities.
Examples of when we have ubiquity
My good friend Andrew Aho over the weekend showed me something that he bought at the local office supplies shop. It was a special pen that, well, did everything.
– He wrote something on paper, and then through his USB, could transfer an exact replica to his computer in his original handwriting.
– He could perform a search on his computer to find a word in his digitised handwritten notes
– He was able to pass the pen over a pre-written bit of text, and it would replay the sounds in the room when he wrote that word (as in the position on the paper, not the time sequence)
– Passing the pen over the word also allowed it to be translated into several other languages
– He could punch out a query with the drawn out calculator, to compute a function
– and a lot more. The company has now created an open API on top of its platform – meaning anyone can now create additional features that build on this technology. It has the equivalent opportunity to when the Web was created as a platform, and anyone was allowed to build on top of it.
The pen wasn’t all that bulky, and it did this simply by having a camera attached, a microphone and special dotted paper that allowed the pen to recognise its position. Imagine if this pen could connect to the Internet, with access to any data, and the cloud computing resources for more advanced queries?
Now watch this TED video to the end, which shows the power when we allow computers to be our sixth sense. Let your imagination run wild as you watch it – and while it does, just think about ubiquitous data, connectivity, and computation which are the pillars for such a future.
Trends right now enabling ubiquity
So from the 10,000 feet view that I’ve just shown you, let’s now zoom down and look at trends occurring right now. Trends that are heading towards this ever growing force towards ubiquity.
From the data standpoint, and where I believe this next wave of innovation will centre on, we need to see two things: Syntactic Interoperability and Semantic Interoperability. Syntactic interoperability is when two or more systems can communicate with each other – so for example, having Facebook being able to communicate with MySpace (say, with people sending messages to each other). Semantic interoperability is the ability to automatically interpret the information exchanged meaningingfully – so when I Google Paris Hilton, the search engine understands that I want a hotel in a city in Europe, not a celebrity.
The Semantic Web and Linked Data is one key trend that is enabling this. It’s interlinking all the information out there, in a way that makes it accessible for humans and machines alike to reuse. Data portability is similarly another trend (of which I try to focus my efforts), where the industry is fast moving to enable us to move our identities, media and other meta data wherever we want to.
…the whole point of working on open building blocks for the social web is much bigger than just creating more social networks: our challenge is to build technologies that enhance the network and serve people so that they in turn can go and contribute to building better and richer societies…I can think of few other endeavors that might result in more lasting and widespread benefits than making the raw materials of human connection and knowledge sharing a basic and fundamental property of the web.
The DiSo Project that Chris leads is an umbrella effort that is spearheading a series of technologies, that will lay the infrastructure for when social networking will become “like air“, as Charlene Li has been saying for the last two years.
One of the most popular open source pieces of software (Drupal) has now for a while been innovating on the data side rather than on other features. More recently, we’ve seen Google announce it will cater better for websites that markup in more structured formats, giving an economic incentive for people to participate in the Semantic Web. API‘s (ways for external entities to access a website’s data and technology) are now flourishing, and are providing a new basis for companies to innovate and allow mashups (like newspapers).
As for computing and connectivity, these are more hardware issues, which will see innovation at a different pace and scale to the data domain. Cloud computing has long been understood as a long term shift, and which aligns with the move to ubiquitous computing. Theoretically, all you will need is an Internet connection, and with the cloud, be able to have computing resources at your disposal.
On the connectivity side, we are seeing governments around the world make broadband access a top priority (like the Australian governments recent proposal to create a national broadband network unlike anything else in the world). The more evident trend in this area however, will be the mobile phone – which since the iPhone, has completely transformed our perception of what we can done with this portable computing device. The mobile phone, when connected to the cloud carrying all that data, unleashes the power that is ubiquity.
And then?
Along this journey, we are going to see some unintended impacts, like how we are currently seeing social media replacing the need for a mass media. Spin-off trends will occur which any reasonable person will not be able to predict, and externalities (both positive and negative) will emerge as we drive towards this longer term trend of everything and everyone being connected. (The latest, for example, being the real time web and the social distribution network powering it).
It’s going to challenge conventions in our society and the way we go about our lives – and that’s something that we can’t predict but just expect. For now, however, the trend is pointing to how do we get ubiquity. Once we reach that, then we can ask the question of what happens after it – that being: what happens when everything is connected. But until then, we’ve got to work out on how do we get everything connected in the first place.
The information value chain I wrote about a while back, although in need of further refinement, underpins my entire thinking in how I think the business
case for data portability exists.
In this post, I am going to give a brief illustration of how interoperability is a win-win for all involved in the digital media business.
To do this, I am going to explain it using the following companies:
– Amazon (EC2)
– Facebook
– Yahoo! (Flickr)
– Adobe (Photoshop Express)
– Smugmug
– Cooliris
How the world works right now
I’ve listed six different companies, each of which can provide services for your photos. Using a simplistic view of the market, they are all competitors – they ought to be fighting to be the ultimate place where you store your photos. But the reality is, they aren’t.
Our economic system is underpinned by a concept known as “comparative advantage“. It means that even if you are the best at everything, you are better off specialising in one area, and letting another entity perform a function. In world trade, different countries specialise in different industries, because by focusing on what you are uniquely good at and by working with other countries, it actually is a lot more efficient.
Which is why I take a value chain approach when explaining data portability. Different companies and websites, should have different areas of focus – in fact, we all know, one website can’t do everything. Not just because of lack of resources, but the conflict it can create in allocating them. For example, a community site doesn’t want to have to worry about storage costs, because it is better off investing in resources that support its community. Trying to do both may make the community site fail.
How specialisation makes for a win-win
With that theoretical understanding, let’s now look into the companies.
Amazon
They have a service that allows you to store information in the cloud (ie, not on your local computer and permanently accessible via a browser). The economies of scale by the Amazon business allows it to create the most efficient storage system on the web. I’d love to be able to store all my photos here.
Facebook
Most of the people I know in the offline world, are connected to me on Facebook. Its become a useful way for me to share with my friends and family my life, and to stay permanently connected with them. I often get asked my friends to make sure I put my photos on Facebook so they can see them.
Yahoo
Yahoo owns a company called Flickr – which is an amazing community of people passionate about photography. I love being able to tap into that community to share and compare my photos (as well as find other people’s photos to use in my blog posts).
Adobe
Adobe makes the industry standard program for graphic design: Photoshop. When it comes to editing my photos – everything from cropping them, removing red-eye or even converting them into different file formats – I love using the functionality of Photoshop to perform that function. They now offer an online Photoshop, which provides similar functionality that you have on the desktop, in the cloud.
Smugmug
I actually don’t have a Smug mug account, but I’ve always been curious. I’d love to be able to see how my photos look in their interface, and be able to tap into some of the features they have available like printing them in special ways.
Cooliris
Cooliris is a cool web service I’ve only just stumbled on. I’d love be able to plug my photos in the system, and see what cool results get output.
Putting it together
I store my photos on Amazon, including my massive RAW picture files which most websites can’t read.
I can pull my photos into Facebook, and tag them how I see fit for my friends.
I can pull my photos into Flickr, and get access to the unique community competitions, interaction, and feedback I get there.
With Adobe Photoshop express, I can access my RAW files on Amazon, to create edited versions of my photos based on the feedback in the comments I received on Flickr from people.
With those edited photos now sitting on Amazon, and with the tags I have on Facebook adding better context to my photos (friends tagging people in them), I pull those photos into Smug mug and create really funky prints to send to my parents.
Using those same photos I used in Smug Mug, I can use them in Cooliris, and create a funky screensaver for my computer.
As a customer to all these services – that’s awesome. With the same set of photos, I get the benefit of all these services, which uniquely provide something for me.
And as a supplier that is providing these services, I can focus on what I am good at – my comparative advantage – so that I can continue adding value to the people that use my offering.
Sounds simple enough, eh? Well the word for that is “interoperability”, and it’s what we are trying to advocate at the DataPortability Project. A world where data does not have borders, and that can be reused again and again. What’s stopping us for having a world like this? Well basically, simplistic thinking that one site should try to do everything rather than focus on what they do best.
Help us change the market’s thinking and demand for data portability.
Open standards matter, but so does the water; and just like water is not what creates a Mona Lisa or a Hoover Dam alone, so too do open standards not really matter that much to what we are trying to do with the DataPortability Project in the longer term. But they matter for the industry, which is why we advocate for them. Here’s why.
Bill Washburn is one of the soft-spoken individuals that has driven a lot of change, like leading the charge to open government technology (the Internet as we know it) to the rest of the world. He’s been around long enough to see trends, so I asked him: why does open always win? What is it about the walled garden that makes it only temporary?
Bill gave me two reasons: technologies need to be easy to implement and they also need to be cheap. It may sound obvious, but below I offer my interpretation why in the context of standards
1) Easy to implement
If you are a developer constantly implementing a standard, you want the easiest one to implement. Having to learn a new standard each time you need to do something is a burden – you want to learn how to do something once and that’s it. And if there is a choice to implement two standards that do the same thing, guess which one will win?
That’s why you will see the technically inferior RSS dominate over ATOM. Both allow syndication and give the end-user the same experience, but for a developer trying to parse it, ATOM is an absolute pain in the buttocks. Compare also JSON and XML – the former being a data structure that’s not even really a standard, and the latter which is one of the older data format standards on Internet. JSON wins out for using asynchronous technologies in the web2.0 world, because it’s just easier to do. Grassroots driven micro-formats and W3C endorsed RDF? Same deal. RDF academically is brilliant – but academic isn’t real world.
2) Cheap to implement
This is fairly obvious – imagine if you had two ways of performing something that did the same thing, but one was free and the other had licensing costs – what do you think a developer or company will use? Companies don’t want to pay licensing fees, especially for non-core activities; and developers can’t afford license fees for a new technology. Entities will bias their choices to the cheaper of the two, like free.
I think an interesting observation can be made about developer communities. Look at people that are the .Net community, compared to say something like Python advocates. You tend to find Python people are more open to collaboration, meetups, and other idea exchanges rather than the .Net developers who keep to themselves (a proprietary language). With the Microsoft owned .Net suite requiring a lot more costs to implement, it actually holds back the adoption of the technology to dominate the market. If people aren’t collaborating as much when compared to rival technologies, that means less innovation, more costs to learning – a longer term barrier to market adoption.
The most important point to make is on the actual companies that push these standards. Let’s say you are Facebook pushing your own standard, which although free, could only be modified by and adapted by the Facebook team. That’s going to cost resources – at the very least, a developer overseeing it. Maybe a team of evangelists to promote your way of thinking; a supervisor to manage this team. If you are the sole organisation in charge of something, it’s going to cost you (not anyone else) a lot of money.
Compare that to an open community effort, where lots of companies and people pool their resources. Instead of one entity bearing the cost, it’s hundreds of entities bearing the cost. On a singular basis, it’s actually cheaper to create a community driven standard. And honestly, when you think about it, why a company fights over what standard gets implemented has nothing to do with their core strategic objectives. Sure they might get some marketing out of it (as the Wikipedia page says “this company created this standard”), but realistically, it’s rewarding more the individuals within these companies who can now put on their resume “I created this technology that everyone is using now”.
Why Open wins
In the short run, open doesn’t win because it’s a longer process, that in part relies on an industry reacting to a proprietary approach. In the long run, Internet history has proven that the above two factors always come to dominate. Why? Because infrastructure is expensive to build and maintain, and usually, it’s better to pool our efforts to build that infrastructure. You don’t want to spend your money on something that’s for the public benefit, only to have no one in the public using it – do you, Mr Corporate Vice-President?
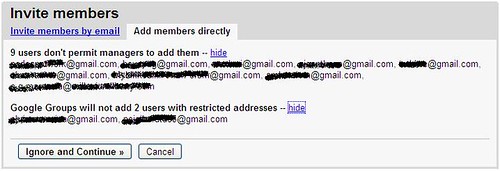
As we were preparing for the upgrade of DataPortability Project’s website, we realised we needed to close off some of our legacy mailing lists…but we didn’t want to lose the hundreds of people already on these mailing lists. So we decide to export the emails and paste them into the new Google group as subscribers.
I then got this error message.
The has to be one of the best error messages I have ever seen. Yes I’m happy that I could port the data from a legacy system/group to a new one, using an open standard (CSV). Yes, I was impressed that the Google Groups team supports this functionality (who I am told is just one Google engineer and are completely understaffed). But what blew me away was the fact Google was able to recognise how to treat these emails.
These particular people have opted to not allow someone to reuse their e-mail, other than the intended purpose for which they submitted it (which was to be subscribed to this legacy Group). Google recognised that and told me I wasn’t allowed to do it as part of my batch add.
That’s Google respecting their users, while making life a hell of a lot easier for me as an administrator of these mailing lists.
I’m happy to be helped out like that, because I don’t want to step on any toes. And these people are happy, because they have control of the way their data is used. That’s what I call “Awesome”.
Chris Saad wrote a good post on the DataPortability Project’s (DPP) blog about how the web works on a peering model. Something we do at the DPP is closely monitor the market’s evolution, and having done this actively for a year now as a formal organisation, I feel we are at the cusp of a lot more exciting times to come. These are my thoughts on why Facebook needs to alter their strategy to stay ahead of the game, and by implication, everyone else who is trying to innovate in this sphere.
It’s a bold statement that you might need to get some background reading to understand my point of view (link above). However once you understand it, all the debates about who “owns” what data, suddenly become irrelevant. Basically access, just like ownership, is possible due to a sophisticated society that recognises peoples rights. Our society has now got to the point where ownership matters less now for the realisation of value, as we now have things in place to do more, through access.
Accessonomics: where access drives value
Let’s use an example to illustrate the point with data. I am on Facebook, MySpace, Bebo, hi5, Orkut, and dozens of other social networking sites that have a profile of me. Now what happens if all of those social networking sites have different profiles of me? One when I was single, one when I was in a relationship, another engaged, and another “it’s complicated”.
If they are all different, who is correct? The profile I last updated of course. With the exception of your birthdate, any data about you will change in the future. There is nothing ‘fixed’ about someone and “owning” a snap shot of them at a particular point of time, is exactly that. Our interests change, as do our closest friends and our careers.
Recognising the time dimension of information means that unless a company has the most recent data about you, they are effectively carrying dead weight and giving themselves a false sense of security (and a false valuation). Facebook’s $3 billion market value is not the data they have in June 2008; but data of people they have access to, of which, that’s the latest version. Sure they can sell to advertisers specific information to target ads, but “single” in May is not as valuable as “single” in November (and even less valuable than single for May and November, but not the months in between).
Facebook Connect and the peering network model
The announcement by Facebook in the last month has been nothing short of brilliant (and when its the CEO announcing, it clearly flags it’s a strategic move for their future, and not just some web developer fun). What they have created out of their Facebook Connect service is shaking up the industry as they do a dance with Google since the announcement of OpenSocial in November 2007. That’s because what they are doing is creating a permanent relationship with the user, following them around the web in their activities. This network business model means constant access to the user. But the mistake is equating access with the same way as you would with ownership: ownership is a permanent state, access is dependent on a positive relationship – the latter of course, being they are not permanent. When something is not permanent, you need strategies to ensure relevance.
When explaining data portability to people, I often use the example of data being like money. Storing your data in a bank allows you better security to house that data (as opposed to under your mattress) and better ability to reuse it (ie, with a theoretical debit card, you can use data about your friends for example, to filter content on a third party site). This Facebook Connect model very much appears to follow this line of thinking: you securely store your data in one place and then you can roam the web with the ability to tap into that data.
However there is a problem with this: data isn’t the same as money. Money is valuable because of scarcity in the supply system, whilst data becomes valuable from reusing and creating derivatives. We generate new information by connecting different types of data together (which by definition, is how information gets generated). Our information economy allows alchemists to thrive, who can generate value through their creativity of meshing different (data) objects.
By thinking about the information value chain, Facebook would benefit more by being connected to other hubs, than having all activity go through it. Instead of data being stored in the one bank, it’s actually stored across multiple banks (as a person, it probably scares you to store all your personal information with the one company: you’d split it if you could). What you want to do as a company is have access to this secure EFT ecosystem. Facebook can access data that occurs between other sites because they are party to the same secured transfer system, even though they had nothing to do with the information generation.
Facebook needs to remove itself from being a central node, and instead, a linked-up node. The node with the most relationships with other sites and hubs wins, because with the more data at your hands, the more potential you have of connecting dots to create unique information.
Facebook needs to think like the Byzantines
A lot more can be said on this and I’m sure the testosterone within Facebook thinks it can colonise the web. What I am going to conclude with is that that you can’t fight the inevitable and this EFT system is effectively being built around Facebook with OpenSocial. The networked peer model will trump – the short history and inherent nature of the Internet proves that. Don’t mistake short term success (ie, five years in the context of the Internet) with the long term trends.
There was once a time where people thought MySpace was unstoppable. Microsoft unbeatable. IBM unbreakable. No empire in the history of the word has lasted forever. What we can do however, is learn the lessons of those that lasted longer than most, like the forgotten Byzantine empire.
Also known as the eastern Roman empire, its been given a separate name by historians because it outlived its western counterpart by over 1000 years. How did they last that long? Through diplomacy and avoiding war as much as possible. Rather than buying weapons, they bought friends, and ensured they had relationships with those around them who had it in their self-interest to keep the Byzantines in power.
Facebook needs to ensure it stays relevant in the entire ecosystem and not be a barrier. They are a cashed up business in growth mode with the potential to be the next Google in terms of impact – but let’s put emphasis on “potential”. Facebook has competitors that are cash flow positive, have billions in the bank, but most importantly of all are united in goals. They can’t afford to fight a colonial war of capturing people identity’s and they shouldn’t think they need to.
Trying to be the central node of the entire ecosystem, by implementing their own proprietary methods, is an expensive approach that will ultimately be beaten one day. However build a peered ecosystem where you can access all data is very powerful. Facebook just needs access, as they can create value through their sheer resources to generate innovative information products: that, not lock-in, is that will keep them up in front.
Just because it’s a decentralised system, doesn’t mean you can’t rule it. If all the kids on a track are wearing the same special shoes, that’s not going to mean everyone runs the same time on the 100 metre dash. They call the patriarch of Constantiniple even to this day “first among equals” – an important figure who worked in parallel to the emperor’s authority during the empire’s reign. And it’s no coincidence that the Byzantine’s outlived nearly all empires known to date, which even to this day, arguably still exists in spirit.
Facebook’s not going to change their strategy, because their short-term success and perception of dominance blinds their eyes. But that doesn’t mean the rest of us need to make that mistake. Pick your fights: realise the business strategy of being a central node will create more heart-ache than gain.
It may sound counter intuitive but less control can actually mean more benefit. The value comes not from having everyone walk through your door, but rather you having the keys to everyone else’s door. Follow the peered model, and the entity with the most linkages with other data nodes, will win.
Life’s been busy, and this blog has been neglected. Not a bad thing – a bit of life-living, work-smacking, exposure to new experiences, and active osmosis from the things I am involved in – is what makes me generate the original perspectives I try to create on this blog.
However to my subscribers (Hi Dad!), let this post make it up to you with some content I’ve created elsewhere.
You already know about the first podcast I did with the Perth baroness Bronwen Clune and the only guy I know who can pull off a mullet Mike Cannon-Brookes of Atlassian . Here’s a recap of some other episodes I’ve done:
Episode two: ex-PwC boy Matthew Macfarlane talks to current PwC boy myself and Bronwen, in his new role as partner of a newly created investment fund Yuuwa Capital. He joined us and told us about what he’s looking for in startups, as he’s about to spend $40million on innovative startups!
Episode three: marketing guru Steve Sammartino , tells us about building a business and his current startup Rentoid.com
Episode four: experienced entrepreneur Martin Hosking shares us lessons and insight, whilst talking about his social commerce art service Red Bubble .
Episode five: “oh-my-God-that-dude-from-TV!” Mark Pesce joins us in discussing that filthy government filter to censor the Internet
Episode six: ex-Fairfax Media strategist Rob Antulov tells us about 3eep – a social networking solution for the amateur and semi-professional sports world.
I’ve also put my data portability hat on beyond mailing list arguments and helped out a new social media service called SNOBS – a Social Network for Opportunistic Business women – with a beginners guide to RSS . You might see me contribute there in future, because I love seeing people pioneer New Media and think Carlee Potter is doing an awesome job – so go support her!
Over and out -regular scheduling to resume after this…
About
Hi - my name is Elias Bizannes, tweetfully known as @EliasBiz where I tend to post more. I've been blessed with not just one but two unpronounceable names: I pronounce them as E-lee-uh(s) bi-ZAH-nis