Mike Melanson interviewed me today over the whole Facebook vs Google standoff. He wrote a nice piece that I recommend you read, but I thought I would expand on what I was quoted on to give my full perspective.
To me, there is a bigger picture battle here, and it’s for us to see true data interoperability on the Internet, of which this is but a minor battle in the bigger war.
I see a strong parallel to global trade and data portability on the web. Like in the days of restrictive trade tariffs that have been progressively demolished with globalisation, the ‘protectionism’ being cried out by each party of protecting their users is but a hollow attempt to satisfy their voters in the short-term, which are the shareholders of each company. This tit-for-tat approach is what governments still practice with trade and people-travel restrictions, but which at the end of the day hurts individuals in the short-term but society as a whole in the longer term. It doesn’t help anyone but give companies (and as we’ve seen historically, governments) a short term sigh of relief.
You only have to look at Australia, which went from having some of the highest trade tariffs in the world in the ’70s to being one of the most open economies in the world by the ’90s. The effect of this is that it made it one of the most competitive economies in the world, which is part of the reason that of all the OECD countries during the recent financial crisis, it managed to be the only economy not to fall into recession. Companies, like the economies governments try to protect, need to be able to react to their market to survive, and they can only do that successfully in the long term by being truly competitive.
The reality is, Facebook and Google are hurting the global information network, as true value unlocks when we have a peered privacy-respecting interoperability network. The belief that value is interpreted as who holds the most data, is a mere attempt to buy time for their true competitive threat — the broader battle for interoperability — which will expose them to compete not on the data they acquired but on their core value as a web service to use that data. These companies need to recognise what their true comparative advantage is and what they can do with that data.
Google and Facebook have improved a lot over the years with regards to data portability, but they continue to make the mistake (if not in words, but in actions) — that locking in the data is the value. Personal information acquired by companies loses value with time — people’s jobs, locations, and even email accounts — change over time and are no longer relevant. What a site really wants is persistent access to a person so they can tap into the more recently updated data, for whatever they need. What Google and Facebook are doing is really hurting them as they would benefit by working together. Having a uniform way of transferring data between their information network silo’s ensures privacy-respecting ways that minimise the risk for the consumer (which they claim to be protecting) and the liberalisation of the data economy means they can in the long term focus on their comparative advantage with the same data.
Has it really been seven years since the first release of WordPress? It seems like just yesterday we were fresh to the world, a new entrant to a market everyone said was already saturated. (As a side note, if the common perception is that a market is finished and that everything interesting has been done already, it’s probably a really good time to enter it.)
WordPress not only has become the most popular blog software and one of the most amazing content management systems around, but its become an amazing platform for innovation. (For example, Ron Kurti and I the other day tried to think outside-of-the-box for employee expense reports at Vast. So we hacked a wordpress blog to do so – and we could do it in minutes of effort.) Not only that, but the wordpress.org founder built a company around the software and it’s become a very successful company on the web. Thank God he entered at a time of market saturation.
But it doesn’t stop there. Consider the following stories as well, which highlight lessons in building amazing companies.
When Google launched as a search engine, everyone though the space had matured and had little opportunity. Google has now become one of the most influential companies in history.
When Apple launched the iPod, the MP3 player market had been well established. No one at the time would have thought another product from this yesteryear company, would be the product that help it reinvent the company to become the second largest US company today.
When Facebook launched, it was yet another social network well after Friendster (the inventor) and MySpace (the populariser). In fact, I remember analysts calling 2003 the year of the social network – a year before Facebook was even invented. And now, Mark Zuckerberg has created a company that will transform online advertising, has helped contribute to the new billion dollar virtual goods industry, and is going to lead the charge for the semantic web.
In 1990, hyptertext systems had saturated the market since the 1960s when Ted Nelson coined the term. That didn’t stop Tim Berners-Lee, who that year invented the web – yet another hyptertext system. The Web is not a company like the ones above, but the Web is in league that few inventions in the history of the humanity have ever achieved.
Naval Ravikant has told me that in the consumer web space, the first mover advantage is so great that a company can own the space – the logic being they are so far ahead in execution and their brand is synonymous with the industry, that they become impossible to topple. This fact is why I think a lot of entrepreneurs in the Internet space seem consumed with creating a business that introduces a new concept product, as opposed to a better product – which is what the above companies did..
I think there is something to be to be said about the last mover advantage: monitor the patterns of something new, innovate on the implementation, and then out-execute the guys that invented the concept. And out execute you can easily, as the inventors are probably caught up in organisational inertia due to conflicting innovations, not to mention a misunderstanding of what actually made them successful in the first place.
As it was said once: the guy who invented the first wheel was an idiot; but the guy who invented the other three was a genius.
I think it’s about time for a personal dashboard to track and view what happens to what we share online. This would have two primary uses: 1) Privacy: I’d have a better idea of what’s publicly known about myself, and
2) Analytics: Like any content publisher, I’d be interested in checking my stats and trends.
It’s a protocol being spearheaded by Eve Maler, who is also one of the co-inventors of XML, one of the web’s core technologies and a co-founder of SAML which is one of the major identity technologies around (think OpenID but for enterprise).
It allows you to have a dashboard, where you can manage sites subscribed to your data via URL’s. You can set access rules to those URL’s, like when they expire and what data they can use. It’s like handing web-services a pipe that you can block and throttle the flow of data as you wish, all managed from a central place. Not only does this mean better privacy, but it also satisfies your request for analytics as you can see who is pulling your data.
So now my wish: let’s spread awareness of great efforts like this. 🙂
Facebook announced today that they became cash-flow positive in the last quarter. This is a big deal, and should be looked at in the broader context of the Internet’s development and the economy’s resurgence.
The difference between a start-up and a growth company
There are four stages in the life-cycle of a business: start-up, growth, maturity, and decline.
In tech, we tend to obsess over the “start-up” – a culture that idolises small, nimble teams innovating every day. Bu there is a natural consequence of getting better, bigger, and more dominant in a market – you become a big company. And big company’s can do a lot more (and less) than when they could as startup’s.
Without going too much into the difference between the cycles, it’s worth mentioning that a functional definition to differentiate a “startup” business from a “growth” business is its financial performance. Meaning, a startup can be one who has revenues and expenses – but the revenues don’t tend to cover the operating costs of a business. A growth business on the other hand, is experiencing the same craziness of a start-up – but is now self-supporting because its revenues can over its costs.
This makes a big difference in a company, lest of all longer term sustainability. When a business is cashflow negative, it risks going bankrupt and management’s attention can be distracted by attempts to raise money. But at least now with Facebook finally going cash-flow positive, it has one less thing to worry about and can now grow with a focus less on survival and more on dominance.
Looking at history
Several years after the Dot Com bubble, I remember reading an article by a switched on journalist. He was talking about the sudden growth of Google, and how Google could potentially bring the tech industry back from the ashes. He was right.
Google has created a lot of innovative products, but its existence has had two very important impacts on the Internet’s development.
First of all, there was adsense – a innovative new concept in advertising that millions of websites around the world could participate in. Google provided the web a new revenue model that has supported millions of content creators, utility providers, and marketplaces powered by the Internet.
Secondly, Google created a new exit model. Startup’s now had a new hungry acquisition machine, giving startups more opportunities to get funded as Venture Capitalists no longer relied on an IPO to make their money – which had now been effectively killed thanks to the over-engineered requirements of Sarbanes Oxley.
Why Facebook going cashflow positive is a big deal
Facebook is doing what Google did, and it’s money and innovation will drive the industry to a new level. Better still, its long been regarded that technology is what helps economies achieve growth again, and so the growth of Facebook will not only see a rebuilding of the web economy but also of the American one. The multiplier effect of Facebook funding the ecosystem will be huge.
And just like Google, Facebook will likely be pioneering a new breed of advertising network that benefits the entire Internet. And even if it fails in doing that, its cash will at least fund the next hype cycle of the web.
So mark this day as when the nuclear winter has ended – it’s spring time boys and girls. We my not have a word like Web2.0 to describe the current state of the Internets evolution, but whatever its called, that era has now begun.
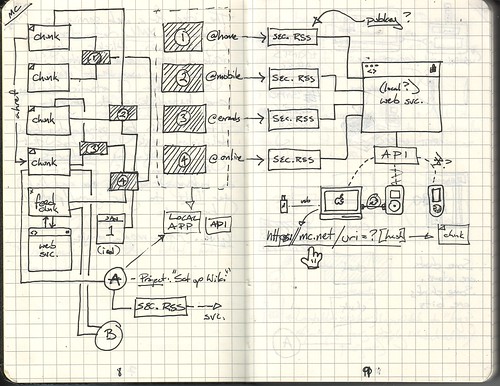
Application Programming Interfaces – better known in the technology industry as API’s – have come out as one of the most significant innovations in information technology. What at first appears a geeky technical technique for developers to play with, is now evolving into something that will underpin our very society (assuming you accept information has, is, and will be the the crux of our society). This post explores the API and what it means for business.
What is it?
In very simple terms, an API is a set of instructions a service declares, that outsiders can use to interact with it. Google Maps has one of the most popular API’s on the Internet and provides a good example of their power. Google hosts terabytes of data relating to its mapping technology, and it allows developers not affiliated with Google to build applications on top of Google’s. For example, thousands of websites like the NYTimes.com have integrated Google’s technology to enhance their own.
An example more familiar with ordinary consumers would be Facebook applications. Facebook allows developers through an API to create ‘apps’ that have become one of the main sources of entertainment on Facebook, the world’s most popular social networking site. Facebook’s API determines how developers can build apps that interact with Facebook and what commands they need to specify in order to pull out people’s data stored in Facebook. It’s a bit like a McDonald’s franchise – you are allowed to use McDonald’s branding, equipment and supplies, so long as you follow the rules in being a franchisee.
API’s have become the centre of the mashup culture permeating the web. Different websites can interact with each other – using each others technology and data – to create innovative products.
What incentive do companies have in releasing an API?
That’s the interesting question that I want to explore here. It’s still early days in the world of API’s, and a lot of companies seem to offer them for free – which seems counter-intuitive. But on closer inspection, it might not. Free or not, web businesses can create opportunity.
Free doesn’t mean losing
An API that’s free has the ability to generate real economic value for a new web service. For example, Search Engine Optimisation (SEO) has become a very real factor in business success now. Becoming the top result for the major search engines generates free marketing for new and established businesses.
In order for companies to boost their SEO rankings, one of the things they need to do is have a lot of other websites pointing links at them. And therein flags the value of an open API. By allowing other people to interact with your service and requiring some sort of attribution, it enables a business to boost their SEO dramatically.
Scarcity is how you generate value
One of the fundamental laws of economics, is that to create value, you need something to be scarce. (That’s why cash is tightly controlled by governments.) Twitter, the world’s most popular micro-blogging service, is famous for the applications that have been built on their API (with over 11,000 apps registered). And earlier this year, they really got some people’s knickers in a knot when they decided to limit usage of the API.
Which is my eyes was sheer brilliance by the team at Twitter.
By making their API free, they’ve had hundreds of businesses build on top of it. Once popular, they could never just shut the API off and start charging access for it – but by introducing some scarcity, they’ve done two very important things: they are managing expectations for the future ability to charge additional access to the API and secondly, they are creating the ability to generate a market.
The first point is better known in the industry as the Freemium model. Its become one of the most popular and innovative revenue models in the last decade on the Internet. One where it’s free for people to use a service, but they need to pay for the premium features. Companies get you hooked on the free stuff, and then make you want the upgrade.
The second point I raised about Twitter creating a market, is because they created an opportunity similar to the mass media approach. If an application dependent on the API needs better access to the data, they will need to pay for that access. Or why not pay someone else for the results they want?
Imagine several Twitter applications that every day calculate a metric – that eats their daily quota like no tomorrow – but given it’s a repetitive standard task, doesn’t require everyone having to do it. If the one application of say a dozen could generate the results, they could then sell it to the other 11 companies that want the same output. Or perhaps, Twitter could monitor applications generating the same requests and sell the results in bulk.
That’s the mass media model: write once, distribute to many. And sure, developers can use up their credits within the limit…or they can instead pay $x per day to get the equivalent information pre-mapped out. By limiting the API, you create an economy based on requests (where value comes through scarcity) – either pay a premium API which gives high-end shops more flexibility or pay for shortcuts to pre-generated information.
With reference to my model, the API offers the ability for a company to specialise at one stage of the value chain. The processing of data can be a very intensive task, and require computational resources or raw human effort (like a librarian’s taxonomy skills). Once this data is processed, a company can sell that output to other companies, who will generate information and knowledge that they in turn can sell.
I think this is one of the most promising opportunities for the newspaper industry. The New York Times last year announced a set of API’s (their first one being campaign finance data), that allows people to access data about a variety of issues. Developers can then query this API, and generate unique information. It’s an interesting move, because it’s the computer scientists that might have found a future career path for journalists.
Journalists skills in accessing sources, determining significance of information, and conveying it effectively is being threatened with the democratisation of information that’s occurred due to the Internet. But what the NY Times API reflects, is a new way of creating value – and it’s taking more of a librarian approach. Rather than journalism become story-centric, their future may be one where it is data based, which is a lot more exciting than it sounds. Journalists yesterday were the custodians of information, and they can evolve that role to one of data instead. (Different data objects connected together, by definition, is what creates information.)
A private version of the semantic web and a solution for data portability
The semantic web is a vision by the inventor of the World Wide Web, which if fully implemented, will make the advances of the Internet today look like prehistory. (I’ve written about the semantic web before to give those new to the subject or skeptical.) But for those that do know of it, you probably are aware of one problem and less aware of another.
The obvious problem is that it’s taking a hell of a long time to see the semantic web happen. The not so obvious problem, is that it’s pushing for all data and information to be public. The advocacy of open data has merit, but by constantly pushing this line, it gives no incentive for companies to participate. Certainly, in the world of data portability, the issue of public availability of your identity information is scary stuff for consumers.
Enter the API.
API’s offer the ability for companies to release data they have generated in a controlled way. It can create interoperability between different services in the same way the semantic web vision ultimately wants things to be, but because it’s controlled, can overcome this barrier that all data needs to be open and freely accessible.
Concluding thoughts
This post only touches on the subject. But it hopefully makes you realise the opportunities created by this technology advance. It can help create value without needing to outlay cash; new monetisation opportunities for business; additional value in society due to specialisation; and the ability to bootstrap the more significant trends in the Web’s evolution.
May is real time month: everyone is now saying the latest trend for innovation is the real time web. Today, we hear that Larry Page, co-founder of Google, confirming to Loic Le Meur that real time search was overlooked by Google and is now a focus for their future innovation.
Friendfeed does real time better than anyone else. Facebook rules when it comes to the activity stream of a person ‚Äì meaning, tracking an individuals life and to some extent media sharing. Twitter rules for sentiment, as it’s like one massive chat room, and to some extent link sharing. But Friendfeed, quite frankly, craps all over Facebook and Twitter in real time search.
Why? Three reasons:
1) It‚Äôs an aggregator. The fundamental premise of the service is in aggregating people‚Äôs lives and their streams. People don‚Äôt even have to ever visit Friendfeed other than an initial sign up. Once someone confirms their data sources, Friendeed has a crawler constantly checking an individuals life stream AND that’s been validated as their own. It doesn‚Äôt rely on a person Tweeting a link, or sharing a video ‚Äì it‚Äôs done automatically through RSS.
2) It’s better suited for discovery. The communities for Twitter, Facebook, and Friendfeed are as radically different as America, Europe, and Asia are in cultures. People that use Friendfeed literally sit there discovering new content, ranking it with their “likes” and expanding it with their comments to items. It’s a social media powerhouse.
3) It’s better technology. Don’t get me wrong, Facebook has an amazing team. But they don’t have the same focus. With less people and less money – but with a stricter focus – Friendfeed actually has a superior product specifically when it comes to real time search. Their entire service is built around maximizing it.
Up until now, I‚Äôve been wondering about Friendfeed’s future. It has a brilliant team rolling out features I didn‚Äôt even realise I needed or could have. But I couldn’t see the value proposition ‚Äì or rather, I don‚Äôt have the time to get the value out of Friendfeed because I have a job that distracts me from monitoring that stream!
But now it‚Äôs clear to me that Friendfeed is a leader in the pack – a pack that’s now shaping into a key trend of innovation. And given the fact the creator of Gmail and Adsense is one of the co-founders, I couldn‚Äôt imagine a better fit for Google.
In the half century since the Internet was created – and the 20 years that the web was invented – a lot has changed. More recently, we’ve seen the Dot Com bubble and the web2.0 craze drive new innovations forward. But as I’ve postulated before, those eras are now over. So what’s next?
Well, ubiquity of course.
Huh?
Let’s work backwards with some questions to help you understand.
Why do we now need ubiquity, and what exactly that means, requires us to think of another two questions. The changes brought by the Internet are not one big hit, but a gradual evolution. For example, “Open” has existed since the first days of the Internet in culture: it wasn’t a web2.0 invention. But “openess” was recognised by the masses only in web2.0 as a new way of doing things. This “open” culture had profound consequences: it led to the mass socialisation around content, and recognition of the power that is social media.
As the Internet’s permeation in our society continues, it will generate externalities that affect us (and that are not predictable). But the core trend can be identifiable, which is what I hope to explain in this post. And by understanding this core trend, we can comfortably understand where things are heading.
So let’s look at these two questions:
1) What is the longer term trend, that things like “open” are a part of?
2) What are aspects of this trend yet to be fully developed?
The longer term trend
The explanation can be found into why the Internet and the web were created in the first place. The short answer: interoperability and connectivity. The long answer – keep reading.
Without going deep into the history, the reason why the Internet was created was so that it could connect computers. Computers were machines that enabled better computation (hence the name). As they had better storage and querying capacities than humans, they became the way the US government (and large corporations) would store information. Clusters of these computers would be created (called networks) – and the ARPANET was built as a way of building connections between these computers and networks by the US government. More specifically, in the event of a nuclear war and if one of these computing networks were eliminated – the decentralised design of the Internet would allow the US defense network to rebound easily (an important design decision to remember).
The web has a related but slightly different reason for its creation. Hypertext was conceptualised in the 1960s by a philosopher and scientist, as a way of harnessing computers to better connect human knowledge. These men were partly inspired by an essay written in the the 1940s called “As We May Think“, where the chief scientist of the United States stated his vision whereby all knowledge could be stored on neatly categorised microfirm (the information storage technology at the time), and in moments, any knowledge could be retrieved. Several decades of experimentation in hypertext occurred, and finally a renegade scientist created the World Wide Web. He broke some of the conventions of what the ideal hypertext system would look like, and created a functional system that solved his problem. That being, connecting all these distributed scientists around the world and their knowledge.
So as it is clearly evident, computers have been used as a way of storing and manipulating information. The Internet was invented to connect computing systems around the world; and the Web did the same thing for the people who used this network. Two parallel innovative technologies (Internet and hypertext) used a common modern marvel (the computer) to connect the communication and information sharing abilities of machines and humans alike. With machines and the information they process, it’s called interoperability. With humans, it’s called being connected.
But before we move on, it’s worth noting that the inventor of the Web has now spent a decade advocating for his complete vision: a semantic web. What’s that? Well if we consider the Web as the sum of human knowledge accessible by humans, the Semantic Web is about allowing computers to be able to understand what the humans are reading. Not quite a Terminator scenario, but so computers can become even more useful for humans (as currently, computers are completely dependent on humans for interpretation).
What aspects of the trend haven’t happened yet?
Borders have been broken down that previously restrained us. The Internet and Hyptertext are enabling connectivity with humans and interoperability for computer systems that store information. Computers in turn, are enabling humans to process tasks that could not be done before. If the longer term trend is connecting and bridging systems, then the demon to be demolished are the borders that create division.
So with that in mind, we can now ask another question: “what borders exist that need to be broken down?” What it all comes down to is “access”. Or more specifically, access to data, access to connectivity, and access to computing. Which brings us back to the word ubiquity: we now need to strive to bridge the gap in those three domains and make them omnipresent. Information accessible from anywhere, by anyone.
Let’s now look at this in a bit more detail
– Ubiquitous data: We need a world where data can travel without borders. We need to unlock all the data in our world, and have it accessible by all where possible. Connecting data is how we create information: the more data at our hands, the more information we can generate. Data needs to break free – detached from the published form and atomised for reuse.
– Ubiquitous connectivity: If the Internet is a global network that connects the world, we need to ensure we can connect to that network irregardless of where we are. The value of our interconnected world can only achieve its optimum if we can connect wherever with whatever. At home on your laptop, at work on your desktop, on the streets with your mobile phone. No matter where you are, you should be able to connect to the Internet.
– Ubiquitous computing: Computers need to become a direct tool available for our mind to use. They need to become an extension of ourselves, as a “sixth sense”. The border that prevents this, is the non-assimilation of computing into our lives (and bodies!). Information processing needs to become thoroughly integrated into everyday objects and activities.
Examples of when we have ubiquity
My good friend Andrew Aho over the weekend showed me something that he bought at the local office supplies shop. It was a special pen that, well, did everything.
– He wrote something on paper, and then through his USB, could transfer an exact replica to his computer in his original handwriting.
– He could perform a search on his computer to find a word in his digitised handwritten notes
– He was able to pass the pen over a pre-written bit of text, and it would replay the sounds in the room when he wrote that word (as in the position on the paper, not the time sequence)
– Passing the pen over the word also allowed it to be translated into several other languages
– He could punch out a query with the drawn out calculator, to compute a function
– and a lot more. The company has now created an open API on top of its platform – meaning anyone can now create additional features that build on this technology. It has the equivalent opportunity to when the Web was created as a platform, and anyone was allowed to build on top of it.
The pen wasn’t all that bulky, and it did this simply by having a camera attached, a microphone and special dotted paper that allowed the pen to recognise its position. Imagine if this pen could connect to the Internet, with access to any data, and the cloud computing resources for more advanced queries?
Now watch this TED video to the end, which shows the power when we allow computers to be our sixth sense. Let your imagination run wild as you watch it – and while it does, just think about ubiquitous data, connectivity, and computation which are the pillars for such a future.
Trends right now enabling ubiquity
So from the 10,000 feet view that I’ve just shown you, let’s now zoom down and look at trends occurring right now. Trends that are heading towards this ever growing force towards ubiquity.
From the data standpoint, and where I believe this next wave of innovation will centre on, we need to see two things: Syntactic Interoperability and Semantic Interoperability. Syntactic interoperability is when two or more systems can communicate with each other – so for example, having Facebook being able to communicate with MySpace (say, with people sending messages to each other). Semantic interoperability is the ability to automatically interpret the information exchanged meaningingfully – so when I Google Paris Hilton, the search engine understands that I want a hotel in a city in Europe, not a celebrity.
The Semantic Web and Linked Data is one key trend that is enabling this. It’s interlinking all the information out there, in a way that makes it accessible for humans and machines alike to reuse. Data portability is similarly another trend (of which I try to focus my efforts), where the industry is fast moving to enable us to move our identities, media and other meta data wherever we want to.
…the whole point of working on open building blocks for the social web is much bigger than just creating more social networks: our challenge is to build technologies that enhance the network and serve people so that they in turn can go and contribute to building better and richer societies…I can think of few other endeavors that might result in more lasting and widespread benefits than making the raw materials of human connection and knowledge sharing a basic and fundamental property of the web.
The DiSo Project that Chris leads is an umbrella effort that is spearheading a series of technologies, that will lay the infrastructure for when social networking will become “like air“, as Charlene Li has been saying for the last two years.
One of the most popular open source pieces of software (Drupal) has now for a while been innovating on the data side rather than on other features. More recently, we’ve seen Google announce it will cater better for websites that markup in more structured formats, giving an economic incentive for people to participate in the Semantic Web. API‘s (ways for external entities to access a website’s data and technology) are now flourishing, and are providing a new basis for companies to innovate and allow mashups (like newspapers).
As for computing and connectivity, these are more hardware issues, which will see innovation at a different pace and scale to the data domain. Cloud computing has long been understood as a long term shift, and which aligns with the move to ubiquitous computing. Theoretically, all you will need is an Internet connection, and with the cloud, be able to have computing resources at your disposal.
On the connectivity side, we are seeing governments around the world make broadband access a top priority (like the Australian governments recent proposal to create a national broadband network unlike anything else in the world). The more evident trend in this area however, will be the mobile phone – which since the iPhone, has completely transformed our perception of what we can done with this portable computing device. The mobile phone, when connected to the cloud carrying all that data, unleashes the power that is ubiquity.
And then?
Along this journey, we are going to see some unintended impacts, like how we are currently seeing social media replacing the need for a mass media. Spin-off trends will occur which any reasonable person will not be able to predict, and externalities (both positive and negative) will emerge as we drive towards this longer term trend of everything and everyone being connected. (The latest, for example, being the real time web and the social distribution network powering it).
It’s going to challenge conventions in our society and the way we go about our lives – and that’s something that we can’t predict but just expect. For now, however, the trend is pointing to how do we get ubiquity. Once we reach that, then we can ask the question of what happens after it – that being: what happens when everything is connected. But until then, we’ve got to work out on how do we get everything connected in the first place.
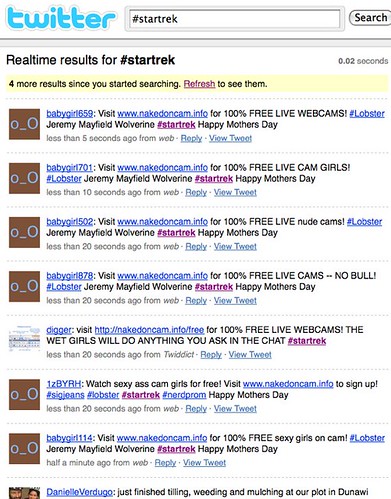
Whilst innovation is always a good thing to see, let’s not forget some of the more innovative people in our world actually are the bad guys. Ladies and gentlemen – introducing real time spam.
The screening of the popular new release movie Star Trek was one of the biggest topics being discussed in the Twitter community (a community where the real time web is at its biggest right now). And the spammers have bombarded it.
The Real Time Web has massive opportunity for our society – especially when everyone is connected. But it also makes us vulnerable – as real time means a captured attention from the audience. And like a police car chase constantly trying to out the bad guys, trying to regulate the Real Time Web could be a challenge.
It’s been a great experience (still going – send us your feedback!) and I’ve learned a lot. But something really strikes me which I think should be shared. It’s how little has changed since the last start-up camp and how stupid companies are – but first, some background.
The above mentioned product we launched, is a service that allows people to discover events and activities that they would be interested in. We have a lot of thoughts on how to grow this – and I know for a fact, finding new things to do in a complex city environment as time-poor adults, is a genuine issue people complain often about. As Mick Liubinskas said “Matching events with motivation is one of the Holy Grails of online businesses” and we’re building tools to allow people to filter events with minimal effort.
So as “entrepreneurs” looking to create value under an artificial petri dish, we recognised that existing events services didn’t do enough to filter events with user experience in mind. By pulling data from other websites, we have created a derivative product that creates value without necessarily hurting anyone. Our value proposition comes from the user experience in simplicity (more in the works once the core technology is set-up) and we are more than happy to access data from other providers in the information value chain on the terms they want.
The problem is that they have no terms! The concept of an API is one of the core aspects of the mashup world we live in, firmly entrenched within the web’s culture and ecosystem. It’s something that I believe is a dramatic way forward for the evolution of the news media and it’s a complementary trend that is building the vision of the semantic web. However nearly all the data we have hasn’t been done through an API which can regulate the way we use the data; instead, we’ve had to scrape it.
Scraping is a method of telling a computer how data is structured on a web page, which you then ‘scape’ data from that template presentation on a website. A bit like highlighting words in a word document with a certain characteristic and pulling all the words you highlighted into your own database. Scraping has a negative connotation as people are perceived to be stealing content and re-using it as their own. The truth of the matter is, additional value gets generated when people ‘steal’ information products: data is an object, and by connecting it with other objects – those relationships – are what create information. The potential to created unique relationships with different data sets, means no two derivative information products are the same.
So why are companies stupid
Let’s take for example a site that sells tickets and lists information about them. If you are not versed in the economics of data portability (which we are trying to do with the DataPortability Project), you’d think that if Activity Horizon is scraping ‘their’ data, that’s a bad thing as we are stealing their value.
WRONG!
Their revenue model is based on people buying tickets through their site. So by us reusing their data and creating new information products, we are actually creating more traffic, more demand, more potential sales. By opening up their data silo, they’ve actually opened up more revenue for themselves. And by opening up their data silo, they not only control the derivatives better but they can reduce the overall cost of business for everyone.
Let’s use another example: a site that aggregates tickets and doesn’t actually sell them (ie, their revenue model isn’t through transactions but attention). Activity Horizon could appear to be a competitor right? Not really – because we are pulling information from them (like they are pulling information from the ticket providers). We’ve extracted and created a derivative product, that brings a potential audience to their own website. It’s repurposing information in another way, to a different audience.
The business case for open data is something I could spend hours talking about. But it all boils down to this: data are not like physical objects. Scarcity does not determine the value of data like it does with physical goods. Value out of data and information comes through reuse. The easier you make it for others to resuse your data, the more success you will have.
I’ve just posted an explanation on the DataPortability Blog about delegated authentication and the Open Standard OAuth. I give poor Twitter a bit of attention by calling them irresponsible (which their password anti-pattern is – a generic example being sites that force people to give up their passwords to their e-mail account, to get functionality like finding your friends on a social network) but with their leadership they will be a pin-up example which we can promote going forward and well placed in this rapidly evolving data portability world. I thought the news would have calmed down by now, but new issues have come to light further highlighting the importance of some security.
With the death of Web 2.0, the next wave of growth for the Web (other than ‘faster, better, cheaper’ tech for our existing communications infrastructure) will come from innovation on the data side. Heaven forbid another blanket term for this next period, which I believe we will see the rise of when Facebook starts monetising and preparing for an IPO, but all existing trends outside of devices (mobile) and visual rendering (3D Internet) seem to point to this. That is, innovation on machine-to-machine technologies, as opposed to the people-to-machine and people-to-people technologies that we have seen to date. The others have been done and are being refined: machine-to-machine is so big it’s a whole new world that we’ve barely scratched the surface of.
But enough about that because this isn’t a post on the future – it’s on the current – and how pathetic current practices are. I caught up with Carlee Potter yesterday – she’s a young Old Media veteran who inspired by the Huffington Post, wants to pioneer New Media (go support her!). Following on from our discussion, she writes in her post that she is pressured by her friends to add applications on services like Facebook. We started talking about this massive cultural issue that is now being exported to the mainstream, where people freely give up personal information – not just the apps accessing it under Facebook’s control, but their passwords to add friends.
I came to the realisation of how pathetic this password anti-pattern is. I am very aware that I don’t like the fact that various social networking sites ask me for private information like my e-mail account, but I had forgotten how used to the process I’ve become to this situation that’s forced on us (ie, giving up our e-mail account passsword to get functionality).
Argument’s that ‘make it ok’ are that these types of situations are low risk (ie, communication tools). I completely disagree, because reputational risk is not something easily measured (like financial risk which has money to quantify), but that’s not the point: it’s contributing to a broader cultural acceptance, that if we have some trust of a service, we will give them personal information (like passwords to other services) so we can get increased utility out of that service. That is just wrong, and whilst the data portability vision is about getting access to your data from other services, it needs to be done whilst respecting the privacy of yourself and others.
Inspired by Chris Messina, I would like to see us all agree on making 2009 the year we kill the password anti-pattern. Because as we now set the seeds for a new evolution of the web and Internet services, let’s ensure we’ve got things like this right. In a data web where everything is interoperable, something that’s a password anti-pattern is not a culture that bodes us well.
They say privacy is dead. Well it only is if we let it die – and this is certainly one simple thing we can do to control how our personal information about ourselves gets used by others. So here’s to 2009: where we seek the eradication of the password anti-pattern virus!
Hi - my name is Elias Bizannes, tweetfully known as @EliasBiz where I tend to post more. I've been blessed with not just one but two unpronounceable names: I pronounce them as E-lee-uh(s) bi-ZAH-nis