My first experience with a Russian, was on the flight from Dubai to Moscow (connection from Tehran). She was my flight neighbour – a twenty-something singer-musician. She didn?Ǭ¥t say much, although she was taking a swig of her bottle of vodka every five minutes. I presumed she had a serious flight phobia.
Turns out there was no phobia. And that bottle of Vodka was three-quarters finished by the time the plane took off. Apparently, she drinks a bottle a day (I always thought it was an apple a day that kept the doctor away?). And what I thought was a quiet neighbour scared of flying, turned out to be a sarcastic alcoholic who started getting a little too friendly.
Half-way into the flight I decided to put her in her place and end the advances, which made the rest of the flight fairly awkward. But nevertheless, I had just had my first Russian experience: alcoholic, sexual, and incredibly sarcastic. Was this a premonition of the days to come?

Walking across, I saw this fuzzy bit of hair. I thought to myself “that’s a damn big dog”. I walk to the other side of the wall, and it turns out it was a bear.
I had an awesome time in Russia. I spent about ten days there, however to say Moscow and St Petersburg are Russia, is like saying London and Paris are Europe. Needless to say though, alcohol, sexuality, and every type of Russian stereotype you can think of, did feature prominently on my trip.
Russia and alcohol
The contrast between Iran and Russia with regards to alcohol is as startling as say, Osama being elected as the new Pope of the Roman Catholic Church. You can get a bottle of Vodka for practically the same price as a bottle of water. But it is not the cost of alcohol that left me shocked – it was the amount of alcohol Russians drink that shocked me.
An example was on my last day in Moscow, I was on the metro coming from the suburbs with my two buddies from the hostel. On the train, we started talking to some girls next to us – because they looked like they were not a day over 14, and drinking what looked like alcohol (one was also a dead-set ringer for Avril Lavinge). Turns out they were 18, but even so, the legal drinking age is a few years more. It was about 2pm on a Sunday afternoon, and these girls were drinking a 12 per cent alcoholic energy drink. They were also a bit pissed. And no one on the train found this unusual at all.
The streets are filled with people drinking in the middle of the day, like a woman causally having lunch with a beer. It’s not just excessive alcohol, but just a lot of alcohol! Kiosks in Moscow that dot the streets with food and beverages, are also stocked up with alcohol. Alcohol is literally everywhere. Even a seasoned Aussie drinker like me couldn’t help but feel uncomfortable at the drinking culture.

St Petersburg is architectually awesome
Russia and sexuality and beauty
When someone would ask me what my ideal woman looked like, I never knew how to answer that question. In the 30 minute metro ride I had when I first arrived from Moscow airport to the hostel, I saw 28 versions of my ideal woman. Enough said!
I met this dip shit Australian at a nightclub, who been working in the security business for the last eight months. I felt like hitting him because it was such an imbecile, but he did say something that sums it up pretty well (when asked why he likes it so much here): “Because the women are beautiful and the men are ugly”. A little harsh, but so true. Women go out of way to display their femininity – which I suppose is something all European women do, but Russians definitely are a cut above the rest. In boiling hot Iran, all women have to cover themselves completely. In barely five degrees Russia, women are wearing skirts that you see on a beach party. And apparently they even do it in the middle of winter at minus twenty degrees weather.
As for sex: how many times do you go to a nightclub and there are professional strippers on the bar? This one club in St Petersburg, I would be dancing, and then there would be an announcement every hour or so. Everyone would gather around an elevated stage with a pole, and watch the five minute routine – men and women alike watching a strip tease dance that repeatedly left my tongue on the ground. When finished, the disco music would start again, and everyone would resume to dancing as if nothing had just happened.
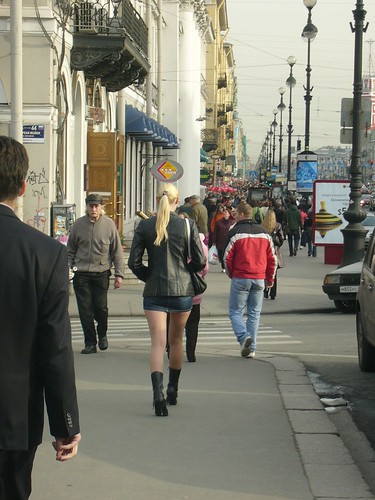
I asked a member of the female species why do they wear such short skirts, in such cold weather. Answer: “Because it looks good”.
Russia and stereotypes
Forget the stereotypes, this is what I experienced: Russians are educated, cultured, and will go out of their way to help a stranger. My shock of this last fact was exacerbated by how I was not expecting people in large cities like Moscow and St Petersburg to be friendly – which are the largest and fourth-largest cities in Europe respectively. A typical example, was when I caught the train to the city centre from the airport. Moscow’s metro is the best in the world – which also means it is bloody complicated, especially for someone still learning the Cyrillic alphabet. I got off the wrong metro station, and asked a man where the hell was I. In his limited English he told me to follow him and walked me to the next station where I was meant to be connecting at – a five minute walk completely out of his way. This is but one example where people went out of their way to help me.
They say that when in Rome, you do as the Romans do. And it?Ǭ¥s not just for experiencing the culture, but for safety reasons as well – you don’t want to stand out as a tourist. But stand out I did. My drunk neighbour on the flight had also made the comment that I looked different. Apparently “American”. Still trying to work that one out.
Fortunately, I didn’t have any problems even though I had foreigner written on my forehead and I did have a bit of fun with it. But the homogeneity of the population is amazing, and people that look different like the people from southern Russia, are constantly pulled up by police on the street for passport and bag checks.

Can you see it, on my forehead? It says “I am a foreigner”
Actually, a slight tangent: in St Petersburg, a university professor from Cambridge university, tried to pick me up. To cut a long story short, I had coffee with him, whilst he attempted to impress me, and invite me back to his apartment for drinks and to see his jacuzzi. The reason I am mentioning this story, is not because of how disgusted I was that a lonely gay man twice my age tried to pick me up, but rather to vent my anger with him because this is my blog and I’ll cry if I want to.
During our discussion, he complained how the Russian academic staff at the university were all straight, which was a weird thing as everyone back in England in his architecture department is gay. And how it bothered him, how they treated him differently. I completely agreed with him, and how bad it is homophobia is so strong here – ever since I got over my schoolboy homophobia, I have always supported gay rights. But then he said two things that made me angry.
The first thing was how he likes St Petersburg because everyone here is white. He doesn’t like the coloured people he has to mix with in London.
The second thing, was how impressive the architecture is in the city. What makes it so impressive, is that the Tsars had millions of slaves dying to make this grand buildings – something a western European ruler would never be able to get away with. And that is what makes them even more special.
So here I am with one of Europe’s leading academics (apparently), sympathising with his inequality, and yet he goes on in the same breath to say how good it is to be in a city full of white people which was built by generations of rulers who had no regards for human life. I felt like getting up and yelling at this maggot to go shove a communist sickle up his arse.
However gay rights are something Russians are not exactly supportive. I had a few conversations with some girls on several issues, and it is interesting to see how traditional minded they are. Point being, how socially conservative the youth are ( just imagine what the adults are like!).

This church in Moscow took 44 years to build, and was later knocked down by Stalin. They recently rebuilt it, using modern technology, in just four years. The interior is amazing.
Then again, the gay thing might have something to do with the fact that there are ten million more women than men in Russia! Settle down though boys – some statistics a friend of mine dug up show that the numbers don?Ǭ¥t actually skew until after age 33 – there are actually slightly more men than women before that. Yet the numbers do imply the affects of three of Russia’s biggest problems: AIDS, Booze, and Chechnya.
There were an estimated 860,000 people living with HIV at the end of 2003 in Russia, and this figure looks set to increase. It has the highest HIV epidemic in all of Europe, although numbers do appear to be falling. The affects of such a disease, especially with an aging population though – is bad.
Alcohol is a serious problem. When Mikhail Gorbachev’s anti-alcohol campaign was launched in 1985, within two years life expectancy for men increased 3.2 years for women and 1.4 for women. Those improvements have since been lost, but it does tell a sad story. Russia, with a population of 143.2 million, has 2.37 million registered alcoholics. The average quantity of pure alcohol per person is 8.7 litres. That’s like everyone in Russia drinking 53 ml of Vodka a day.

Moscows metro: deep, man.
Chechnya is a topic sensitive to Russians. Especially given the terrorist attacks on ordinary Russians by Chechnya’s militants wanting independence. Vladimir Putin recently said he wishes all Chechnyans are flushed down the toilet “We?¢‚Ǩ‚Ñ¢re going to chase terrorists everywhere. If we track them down in a loo, we will rub them out in the loo, too.” This is the head of the government saying this. The fact he can get away with it – and also the reason why he said it – shows how much the war has affected the Russian psyche.
However the wars no doubt have had an impact on population numbers, especially with men who are the ones sent to war. Between 150,000 and 160,000 people have died in the two wars in Chechnya, according to Taus Djabrailov, the head of Chechnya’s interim parliament. The toll includes federal troops, rebel fighters, and civilians who died or went missing during both the first conflict (1994 to 1996) and the second, which began in 1999 and continues today. (Source). And lets not forget Afghanistan, which was Russia’s ‘Vietnam’ in the 1980s.
Mr Putin is also busy putting together the third Russian empire. People don?Ǭ¥t know who it is that controls their country, but as my friend Vera said, one more step backwards and she is out of there. Russia is a country in transformation. A strong man is needed to reorganise a country of its size, seeing as its democratic institutions have grown organically from a sick Soviet Empire (or rather, they have been re-branded as democratic). But a dictator is a dictator. The English-press in Russia seem to buzz with theories on how Putin will hold onto power, as he is legally restricted to two presidential terms. Given the nature of power, it is fairly obvious he will not let go the reigns of the government. However his decision on how he does this, will have huge ramifications on a country struggling to recreate itself.

The double-headed imperial eagle, and the communist star – symbols of two former Russian empires. Wonder what Vladimir is cooking up for his new empire
Economically, the country is not healthy, reliant on oil and arms sales. Apparently 80 per cent of the country’s wealth flows into Moscow – which really makes me wonder what life must be like in the rest of Russia. One set of figures about wages I heard were as such: the average monthly salary is 9000 rubles. A doctor is payed about 3000 by the State (however his secretary probably gets 5000, because she is privately employed). Nine-thousand rubles is about 415 Australian dollars, 315 US dollars, or 260 Euros.
Those numbers are low, but it doesn?Ǭ¥t shock me that much, because I have been to a lot of poor countries where the wages are very similar. But what shocked me was that these are figures for people in Moscow. And in Moscow, I found the prices to be comparable to Sydney and New York. In Australia, the average monthly salary is $4,300 – ten times more than what I was told as the average salary in Russia/Moscow.

You throw money over your shoulder for luck, and the babushkas behind you desperately catch the money. There are more billionaires in Moscow than in any other city in the world, and as you can see, plenty of poverty as well
Russia has one of the worlds richest histories, although a very brutal one as well. A visit to European St Petersburg makes you stagger at the cultural richness of the country, and Moscow’s fast paced, hedonistic consumer lifestyle, makes your head spin to think this was once the communist nerve centre of the world (communism? where?!)
If Russia’s leading two cities have transformed that much in 15 years, I am looking forward to see what it will become in another 15.