I’ve been quoted in RWW and other places as saying the following:
“Users should have the ability to decide upfront what data they permit, not after the handshake has been made where both Facebook and the app developer take advantage of the fact most users don’t know how to manage application privacy or revoke individual permissions,” Bizannes told the website. “Data Portability is about privacy-respecting interoperability and Facebook has failed in this regard.”
Let me explain what I mean by that:
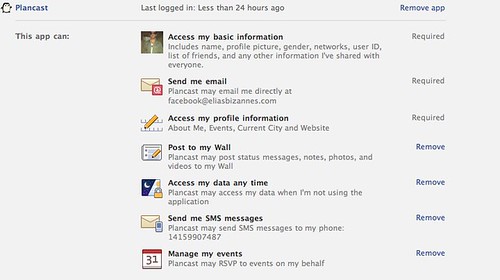
This first screenshot is what users can do with applications. Facebook offers you the ability to manage your privacy, where you even have the ability to revoke individual data authorisations that are not considered necessary. Not as granular as I’d like it (my “basic information” is not something I share equally with “everyone”, such as apps who can show that data outside of Facebook where “everyone” actually is “everyone”), but it’s a nice start.
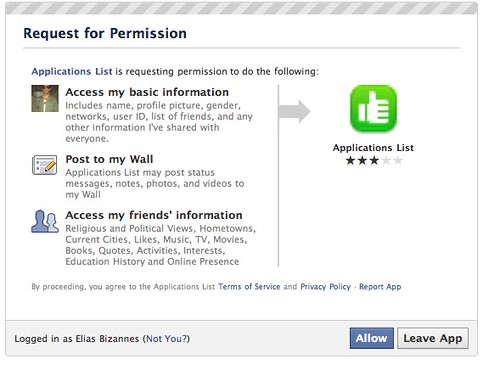
This second screenshot, is what it looks like when you initiate the relationship with the application. Again, it’s great because of the disclosure and communicates a lot very simply.
But what the problem is, is that the first screenshot should be what you see in place of the second screenshot. While Facebook is giving you the ability to manage your privacy, it is actually paying lipservice to it. Not many people are aware that they can manage their application privacy, as it’s buried in a part of the site people seldom use.
The reason why Facebook doesn’t offer this ability upfront is for a very simple reason: people wouldn’t accept apps. When given a yes or no option, users think “screw it” and hit yes. But what if they did this handshake, they were able to tick off what data they allowed or didn’t allow? Why are all these permissions required upfront, when I can later deactivate certain permissions?
Don’t worry, its not that hard to answer. User privacy doesn’t help with revenue revenue growth in as much as application growth which creates engagement. Being a company, I can’t blame Facebook for pursuing this approach. But I do blame them when they pay lipservice to the world and they rightfully should be called out for it.
As Marshall Kirkpatrick eloquently wrote, I’m also another person disappointed that Yahoo! is shutting down Delicious, the social bookmarking site that helped generate the Web 2.0 trend. But this reflects a deeper problem at Yahoo.
How Yahoo’s spreadsheets miss the point
As a “heavy” user myself, it may be ironic to say that I never visit the site; I often will not bookmark a site for month’s. And yet, it hits me like a shot to the heart to hear that it will be shut down. Why? Because it’s so valuable to me. The amount of times I’ve been able to rediscover content I’ve previously read has alone made it valuable — the tagging innovation that Del.icio.us pioneered makes my search for hard-to-recall content much more efficient. But there was even a time, where the most popular links of delicious were my homepage: the quality of the content being shared justified my daily attention in the same way other aggregators have to me like how techmeme.com have.
In fact, I’ve recently rediscovered this as I experiment with the Rockmelt browser, and I check the most popular links via the widget on the side of my browser.
But notice how I don’t visit the website? I might see what links are popular, but that doesn’t mean I will click on them. I don’t visit the actual delicious website and so the metrics the Yahoo management are reviewing are skewed. If advertising is on the site (the only type of revenue model attempted), it would not convert much. They believe no one is using the service, but the truth is, they are.
I never thought the “network” operating model could suffer due to the fact metrics measuring value can’t be quantified. So it’s completely reasonable why a Yahoo management team thinks it time to shut down this service: low on traffic, low on revenue. Numbers in the spreadsheet say this is a loss: let’s kill it, says the MBA.
What we have here though is a management team who not only are out of touch with how people use delicious (potentially because they don’t get the vision that only the founder truly gets — and he’s long gone), but more important, completely misunderstand how to capture the value of this valuable asset (not property). As a point in comparison, Yahoo acquired the other Web2.0 darling Flickr, which is a service I also have been using for over 5 years. And when I say using, I mean a paying customer that has paid his subscription without hesitation every year (which I will note, there are not many services I pay for which makes this even more impressive). Like Delicious, I store data with Flickr that I may not use for a while — but the way it manages my data has become an invaluable tool for my life.
I worry more about Yahoo and any company it acquires
Yahoo’s management should have implemented a subscription model like Flickr, because it’s obvious that a “book marking” site will never get a lot of a traffic (you can book mark sites without having to need to visit delicious.com). Tools like this don’t make money from traffic; and network business models like this generate value beyond the confines of the web property.
With the news breaking, it will now force an action. Either sell it to people who have now seen their cards (in fact, I’ve had friends of mine not in tech ask me how can they put an offer for this!), open-source it (like how Google reacted when etherpad was going to be shut down), or shut it down as they said they want to and lose the opportunity to capture its value. Of course, they could publicly announce they won’t shut it down, but everyone now knows what they think and it will kill the service due to new users being paranoid about their data. Yahoo! gains nothing with this.
But the sad thing about this, is that it’s forced them to ignore the opportunity of potentially being more innovative with the revenue model. And because they failed to do this, this impacts the company more generally — monetisation is key to sustainability and if you have a management that can’t do that (which presumably, is the reason it’s being shut down), then there’s something even more wrong with this new age media company that as Jeff Jarvis has called, has become the last old-media company.
Yahoo is an amazing company, and companies need to make tough decisions sometimes to grow the company. But not understanding the potential of Delicious will go down in web history as one of the great tragedies — and if Yahoo sells it, one of its biggest blunders.
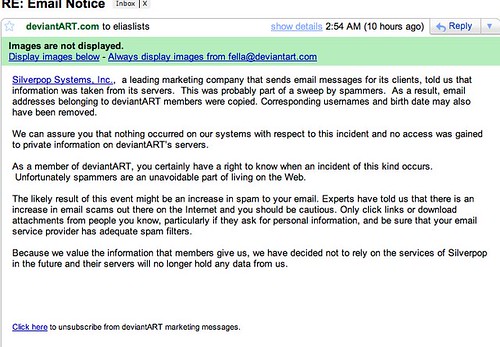
Separately, I today received an email from a web service that I once signed up to but don’t use. The notice says my data has been compromised.
In this case, a partner of deviantART.COM had been shared information of users and it was compromised. Thankfully, I used one of my disposable email addresses so I will not be affected by the spammers. (I create unique email addresses for sites I don’t know or trust, so that I can shut them off if need be.)
But this once again raises the question: why did this happen? Or rather, how did we let this happen?
Delegated authentication and identity management
What was interesting about the Gawker incident was this comment that “if you logged in via Facebook Connect, in which case you’ll be safe.”
Why safe? For the simple reason that when you connect with Facebook Connect, your password details are not exchanged and used as a login. Instead, Facebook will authenticate you and notify the site of your identity. This is the basis of the OpenID innovation, and related to what I said nearly two years ago that it’s time to criminalise the password anti-pattern. You trust one company to store your identity, and you reuse your identity in other companies who provide value if they have access to your identity.
It’s scandals like this remind us for the need of data interoperability and building out the information value chain. I should be able to store certain data with certain companies; have certain companies access certains types of my data; and have the ability to control the usage of my data should I decide so. Gawker and deviantART don’t need my email: they need the ability to communicate with me. They are media companies wanting to market themselves, not technology companies that can innovate on how they protect my data. And they are especially not entitled for some things, like “sharing” data with a partner who I don’t know or can trust, and that subsequently puts me at risk.
Facebook connect is not perfect. But it’s a step in the right direction and we need to propel the thinking of OpenID and its cousin oAuth. That’s it, simple. (At least, until the next scandal.)
Mike Melanson interviewed me today over the whole Facebook vs Google standoff. He wrote a nice piece that I recommend you read, but I thought I would expand on what I was quoted on to give my full perspective.
To me, there is a bigger picture battle here, and it’s for us to see true data interoperability on the Internet, of which this is but a minor battle in the bigger war.
I see a strong parallel to global trade and data portability on the web. Like in the days of restrictive trade tariffs that have been progressively demolished with globalisation, the ‘protectionism’ being cried out by each party of protecting their users is but a hollow attempt to satisfy their voters in the short-term, which are the shareholders of each company. This tit-for-tat approach is what governments still practice with trade and people-travel restrictions, but which at the end of the day hurts individuals in the short-term but society as a whole in the longer term. It doesn’t help anyone but give companies (and as we’ve seen historically, governments) a short term sigh of relief.
You only have to look at Australia, which went from having some of the highest trade tariffs in the world in the ’70s to being one of the most open economies in the world by the ’90s. The effect of this is that it made it one of the most competitive economies in the world, which is part of the reason that of all the OECD countries during the recent financial crisis, it managed to be the only economy not to fall into recession. Companies, like the economies governments try to protect, need to be able to react to their market to survive, and they can only do that successfully in the long term by being truly competitive.
The reality is, Facebook and Google are hurting the global information network, as true value unlocks when we have a peered privacy-respecting interoperability network. The belief that value is interpreted as who holds the most data, is a mere attempt to buy time for their true competitive threat — the broader battle for interoperability — which will expose them to compete not on the data they acquired but on their core value as a web service to use that data. These companies need to recognise what their true comparative advantage is and what they can do with that data.
Google and Facebook have improved a lot over the years with regards to data portability, but they continue to make the mistake (if not in words, but in actions) — that locking in the data is the value. Personal information acquired by companies loses value with time — people’s jobs, locations, and even email accounts — change over time and are no longer relevant. What a site really wants is persistent access to a person so they can tap into the more recently updated data, for whatever they need. What Google and Facebook are doing is really hurting them as they would benefit by working together. Having a uniform way of transferring data between their information network silo’s ensures privacy-respecting ways that minimise the risk for the consumer (which they claim to be protecting) and the liberalisation of the data economy means they can in the long term focus on their comparative advantage with the same data.
1) Awareness.
When Facebook announced their new changes, I tweeted why the hell no one was complaining. Chris Saad and I then wrote one of the first (if not the first) posts that criticised the Facebook move. CNN referenced our post and the entire industry has now gone over the top complaining.
Why didn’t anyone from the major blogs critique the announcement immediately? Why the time lag? For the simple fact there wasn’t awareness – people hadn’t thought about it deeply. And to validate my point, check this recent exchange with a friend in Iran when I asked him how the people of Iran felt about the changes. He had no idea, and when he found out – he got annoyed.
2) The monopoly effect
I love Facebook as a service. But I will also admit, nothing compares to it – I love it for the sole fact it’s the best at what it does. If there was genuine competition with the company, that offered a compelling alternative – I wouldn’t feel as compelled to use it. They win me over due to great technology and user experience, but I’m not loyal to them because of that.
I think Facebook has some security right now because no one is in their class. But they will be matched one day, and I think the reaction would be very different. Rather than tolerate it, people would move away. And whilst Facebook can lock my data and think they own me like I’m their slave, the reality is my data is useless with time – what they need is permanent access to me, and to have that, they need to ensure my relationships with them is permanently ahead of the curve.
I think it’s about time for a personal dashboard to track and view what happens to what we share online. This would have two primary uses: 1) Privacy: I’d have a better idea of what’s publicly known about myself, and
2) Analytics: Like any content publisher, I’d be interested in checking my stats and trends.
It’s a protocol being spearheaded by Eve Maler, who is also one of the co-inventors of XML, one of the web’s core technologies and a co-founder of SAML which is one of the major identity technologies around (think OpenID but for enterprise).
It allows you to have a dashboard, where you can manage sites subscribed to your data via URL’s. You can set access rules to those URL’s, like when they expire and what data they can use. It’s like handing web-services a pipe that you can block and throttle the flow of data as you wish, all managed from a central place. Not only does this mean better privacy, but it also satisfies your request for analytics as you can see who is pulling your data.
So now my wish: let’s spread awareness of great efforts like this. 🙂
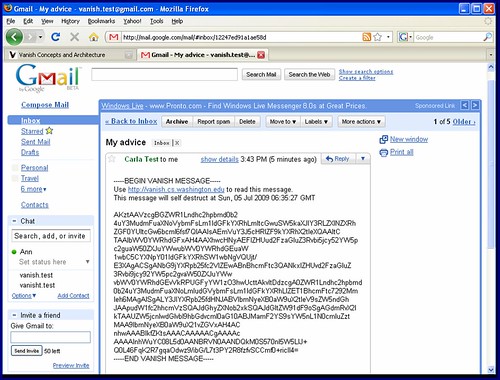
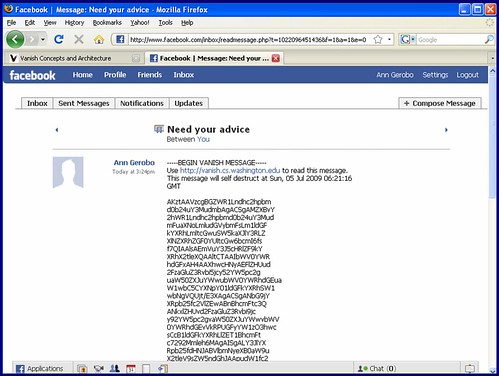
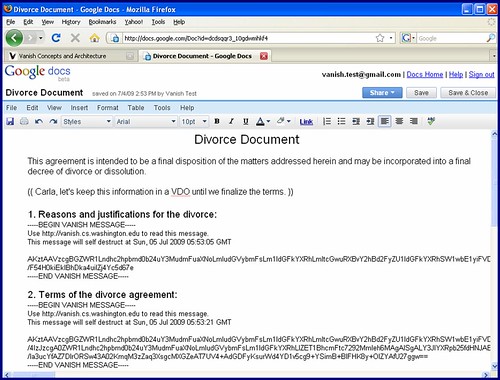
The University of Washington announced today of an invention that allows digital information to expire and “self-destruct”. After a set time period, electronic communications such as e-mail, Facebook posts, word documents, and chat messages would automatically be deleted and becoming irretrievable. Not even the sender will be able the retrieve them, and any copy of the message (like backup tapes) will also have the information unavilable.
Vanish is designed to give people control over the lifetime of personal data stored on the web or in the cloud. All copies of Vanish encrypted data — even archived or cached copies — will become permanently unreadable at a specific time, without any action on the part of a person, third party or centralised service.
As the New York Times notes, the technology of being able to destruct digital data is nothing new. However this particular implementation uses a novel way that combines a time limit and more uniquely, peer-to-peer file sharing that degrades a “key” over time. Its been made available as open source on the Mozilla Firefox browser. Details of the technical implementation can be found on the team’s press release, which includes a demo video.
Implications
Advances like this could have a huge impact on the world, from controlling unauthorised assess to information to reinforcing content-creators copyright. Scenario’s where this technology could benefit
Content. As I’ve argued in the past, news derives its value from how quickly it can be accessed. However, legacy news items can also have value as an archive. By controlling the distribution of unique content like news, publishers have a way of controlling usage of their product – so that they can subsequently monetise the news if used for a different purpose (ie, companies researching the past for information as opposed to being informed by the latest news for day to day decision making)
Identity. Over at the DataPortability Project, we are in the finishing touches of creating our conceptial overview for a standard set of EULA and ToS that companies can adopt. This means, having companies respect your rights to your personal information in a standardised way – think how the Creative Commons has done for your content creations. An important conceptual decision we made, is that a person should have the right to delete their personal information and content – as true portability of your data is more than just reusing it in a different content. Technologies like this allow consumers to control their personal information, despite the fact they may not have possession, as their data resides in the cloud.
Security. Communications between people is so that we can inform each other in the ‘now’. This new world with the Internet capturing all of our conversations (such as chat logs and emails threads) is having us lose control of our privacy. The ability to have chat transcripts and email discussions automatically expire is a big step forward. Better still, if a company’s internal documents are leaked (as was the case with Twitter recently), it can rely on more avenues to limit damage beyond using the court system that would issue injunctions.
There’s a lot more work to be performed on technologies like this. Implementation issues aside, the inline encryption of the information doesn’t make this look sexy. But with a few user interface tweaks, it gives us a strong insight into real solutions for present day problems with the digital age. Even if we simply get companies like Facebook, Google, Microsoft ad Yahoo to agree on a common standard, it will transform the online world dramatically.
Application Programming Interfaces – better known in the technology industry as API’s – have come out as one of the most significant innovations in information technology. What at first appears a geeky technical technique for developers to play with, is now evolving into something that will underpin our very society (assuming you accept information has, is, and will be the the crux of our society). This post explores the API and what it means for business.
What is it?
In very simple terms, an API is a set of instructions a service declares, that outsiders can use to interact with it. Google Maps has one of the most popular API’s on the Internet and provides a good example of their power. Google hosts terabytes of data relating to its mapping technology, and it allows developers not affiliated with Google to build applications on top of Google’s. For example, thousands of websites like the NYTimes.com have integrated Google’s technology to enhance their own.
An example more familiar with ordinary consumers would be Facebook applications. Facebook allows developers through an API to create ‘apps’ that have become one of the main sources of entertainment on Facebook, the world’s most popular social networking site. Facebook’s API determines how developers can build apps that interact with Facebook and what commands they need to specify in order to pull out people’s data stored in Facebook. It’s a bit like a McDonald’s franchise – you are allowed to use McDonald’s branding, equipment and supplies, so long as you follow the rules in being a franchisee.
API’s have become the centre of the mashup culture permeating the web. Different websites can interact with each other – using each others technology and data – to create innovative products.
What incentive do companies have in releasing an API?
That’s the interesting question that I want to explore here. It’s still early days in the world of API’s, and a lot of companies seem to offer them for free – which seems counter-intuitive. But on closer inspection, it might not. Free or not, web businesses can create opportunity.
Free doesn’t mean losing
An API that’s free has the ability to generate real economic value for a new web service. For example, Search Engine Optimisation (SEO) has become a very real factor in business success now. Becoming the top result for the major search engines generates free marketing for new and established businesses.
In order for companies to boost their SEO rankings, one of the things they need to do is have a lot of other websites pointing links at them. And therein flags the value of an open API. By allowing other people to interact with your service and requiring some sort of attribution, it enables a business to boost their SEO dramatically.
Scarcity is how you generate value
One of the fundamental laws of economics, is that to create value, you need something to be scarce. (That’s why cash is tightly controlled by governments.) Twitter, the world’s most popular micro-blogging service, is famous for the applications that have been built on their API (with over 11,000 apps registered). And earlier this year, they really got some people’s knickers in a knot when they decided to limit usage of the API.
Which is my eyes was sheer brilliance by the team at Twitter.
By making their API free, they’ve had hundreds of businesses build on top of it. Once popular, they could never just shut the API off and start charging access for it – but by introducing some scarcity, they’ve done two very important things: they are managing expectations for the future ability to charge additional access to the API and secondly, they are creating the ability to generate a market.
The first point is better known in the industry as the Freemium model. Its become one of the most popular and innovative revenue models in the last decade on the Internet. One where it’s free for people to use a service, but they need to pay for the premium features. Companies get you hooked on the free stuff, and then make you want the upgrade.
The second point I raised about Twitter creating a market, is because they created an opportunity similar to the mass media approach. If an application dependent on the API needs better access to the data, they will need to pay for that access. Or why not pay someone else for the results they want?
Imagine several Twitter applications that every day calculate a metric – that eats their daily quota like no tomorrow – but given it’s a repetitive standard task, doesn’t require everyone having to do it. If the one application of say a dozen could generate the results, they could then sell it to the other 11 companies that want the same output. Or perhaps, Twitter could monitor applications generating the same requests and sell the results in bulk.
That’s the mass media model: write once, distribute to many. And sure, developers can use up their credits within the limit…or they can instead pay $x per day to get the equivalent information pre-mapped out. By limiting the API, you create an economy based on requests (where value comes through scarcity) – either pay a premium API which gives high-end shops more flexibility or pay for shortcuts to pre-generated information.
With reference to my model, the API offers the ability for a company to specialise at one stage of the value chain. The processing of data can be a very intensive task, and require computational resources or raw human effort (like a librarian’s taxonomy skills). Once this data is processed, a company can sell that output to other companies, who will generate information and knowledge that they in turn can sell.
I think this is one of the most promising opportunities for the newspaper industry. The New York Times last year announced a set of API’s (their first one being campaign finance data), that allows people to access data about a variety of issues. Developers can then query this API, and generate unique information. It’s an interesting move, because it’s the computer scientists that might have found a future career path for journalists.
Journalists skills in accessing sources, determining significance of information, and conveying it effectively is being threatened with the democratisation of information that’s occurred due to the Internet. But what the NY Times API reflects, is a new way of creating value – and it’s taking more of a librarian approach. Rather than journalism become story-centric, their future may be one where it is data based, which is a lot more exciting than it sounds. Journalists yesterday were the custodians of information, and they can evolve that role to one of data instead. (Different data objects connected together, by definition, is what creates information.)
A private version of the semantic web and a solution for data portability
The semantic web is a vision by the inventor of the World Wide Web, which if fully implemented, will make the advances of the Internet today look like prehistory. (I’ve written about the semantic web before to give those new to the subject or skeptical.) But for those that do know of it, you probably are aware of one problem and less aware of another.
The obvious problem is that it’s taking a hell of a long time to see the semantic web happen. The not so obvious problem, is that it’s pushing for all data and information to be public. The advocacy of open data has merit, but by constantly pushing this line, it gives no incentive for companies to participate. Certainly, in the world of data portability, the issue of public availability of your identity information is scary stuff for consumers.
Enter the API.
API’s offer the ability for companies to release data they have generated in a controlled way. It can create interoperability between different services in the same way the semantic web vision ultimately wants things to be, but because it’s controlled, can overcome this barrier that all data needs to be open and freely accessible.
Concluding thoughts
This post only touches on the subject. But it hopefully makes you realise the opportunities created by this technology advance. It can help create value without needing to outlay cash; new monetisation opportunities for business; additional value in society due to specialisation; and the ability to bootstrap the more significant trends in the Web’s evolution.
Opera, the Norwegian browser with little under 1% market share of the English market, has made an interesting announcement. Following a much hyped mystery campaign, “Opera Unite” has been announced as a new way to interact with the browser. It transforms the browser into a server – so that your local computer can interact across the Internet in a peer-to-peer fashion. Or in simpler words, you can plug your photos, music and post-it notes into your Opera Unite installation – and be able to access that media anywhere on the Internet, be it another computer or your mobile phone. I view this as conceptually as an important landmark in data portability. The competing browser company Mozilla may lay claim to developing ubiquity, but Opera’s announcement is a big step to ubiquity the concept.
Implications: evolving the cloud to be more democratic I’ve had a test drive, but I’m not going to rehash the functionality here – there is plenty of commentary going on now. (Or better yet, simply check this video.) I don’t think it’s fair to criticise it, as it’s still an early development effort – for example, although I could access my photos on my mobile phone (that were stored on my Mac), I could not stream my music (which would be amazing once they can pull that off). But it’s an interesting idea being pushed by Opera, and it’s worth considering it from the bigger picture.
There is a clear trend to cloud computing in the world – one where all you need is a browser and theoretically you can access anything you need for a computer (as your data, applications and processing power are done remotely). What Opera Unite does, is create a cloud that can be controlled by individuals. It’s embracing the sophistication home users have developed into now that they have multiple computers and devices, connected in the one household over a home wireless network. Different individual computers can act as repositories for a variety of data, and its accessibility can be fully controlled by the individuals.
I think that concept is a brilliant one that brings it to the mass market (and something geeks won’t appreciate as they can already do this). It’s allowing consumers an alternative to storing their data, but still have it accessible “via the cloud”. As the information value chain goes, people can now store their data wherever they wish (like their own households) and then plug those home computers into the cloud to get the desired functionality they desire. So for example, you can store all your precious children pictures and your private health information on your home computer as you’ve chosen that to be your storage facility – but be able to get access to a suite of online functionality that exists in the cloud.
As Chris Messina notes, there is still an opera proxy service – meaning all your data connecting your home computer to your phone and other computers – still go through an Opera central server. But that doesn’t matter, because it’s the concept of local storage via the browser that this embodies. There is the potential for competing, open source attempts in creating a more evenly distributed peer-to-peer model. Opera Unite matters, because it’s implemented a concept people have long talked about – packaged in a dead easy way to use.
Implications: Opera the company
For poor little Opera, this finally gives it a focus to innovate. Its been squashed out of the web browser market, and its had limited success on the mobile phone (its main niche opportunity – although with the iPhone now facing a big threat). Google’s chrome is fast developing into the standard for running SaaS applications over the web. But Opera’s decision to pursue this project is innovating in a new area, and more inline with what was first described as the data portability file system and the DiSo dashboard.
Like all great ideas, I look forward to Unite being copied, refined, and evolve into something great for the broader world.
In the half century since the Internet was created – and the 20 years that the web was invented – a lot has changed. More recently, we’ve seen the Dot Com bubble and the web2.0 craze drive new innovations forward. But as I’ve postulated before, those eras are now over. So what’s next?
Well, ubiquity of course.
Huh?
Let’s work backwards with some questions to help you understand.
Why do we now need ubiquity, and what exactly that means, requires us to think of another two questions. The changes brought by the Internet are not one big hit, but a gradual evolution. For example, “Open” has existed since the first days of the Internet in culture: it wasn’t a web2.0 invention. But “openess” was recognised by the masses only in web2.0 as a new way of doing things. This “open” culture had profound consequences: it led to the mass socialisation around content, and recognition of the power that is social media.
As the Internet’s permeation in our society continues, it will generate externalities that affect us (and that are not predictable). But the core trend can be identifiable, which is what I hope to explain in this post. And by understanding this core trend, we can comfortably understand where things are heading.
So let’s look at these two questions:
1) What is the longer term trend, that things like “open” are a part of?
2) What are aspects of this trend yet to be fully developed?
The longer term trend
The explanation can be found into why the Internet and the web were created in the first place. The short answer: interoperability and connectivity. The long answer – keep reading.
Without going deep into the history, the reason why the Internet was created was so that it could connect computers. Computers were machines that enabled better computation (hence the name). As they had better storage and querying capacities than humans, they became the way the US government (and large corporations) would store information. Clusters of these computers would be created (called networks) – and the ARPANET was built as a way of building connections between these computers and networks by the US government. More specifically, in the event of a nuclear war and if one of these computing networks were eliminated – the decentralised design of the Internet would allow the US defense network to rebound easily (an important design decision to remember).
The web has a related but slightly different reason for its creation. Hypertext was conceptualised in the 1960s by a philosopher and scientist, as a way of harnessing computers to better connect human knowledge. These men were partly inspired by an essay written in the the 1940s called “As We May Think“, where the chief scientist of the United States stated his vision whereby all knowledge could be stored on neatly categorised microfirm (the information storage technology at the time), and in moments, any knowledge could be retrieved. Several decades of experimentation in hypertext occurred, and finally a renegade scientist created the World Wide Web. He broke some of the conventions of what the ideal hypertext system would look like, and created a functional system that solved his problem. That being, connecting all these distributed scientists around the world and their knowledge.
So as it is clearly evident, computers have been used as a way of storing and manipulating information. The Internet was invented to connect computing systems around the world; and the Web did the same thing for the people who used this network. Two parallel innovative technologies (Internet and hypertext) used a common modern marvel (the computer) to connect the communication and information sharing abilities of machines and humans alike. With machines and the information they process, it’s called interoperability. With humans, it’s called being connected.
But before we move on, it’s worth noting that the inventor of the Web has now spent a decade advocating for his complete vision: a semantic web. What’s that? Well if we consider the Web as the sum of human knowledge accessible by humans, the Semantic Web is about allowing computers to be able to understand what the humans are reading. Not quite a Terminator scenario, but so computers can become even more useful for humans (as currently, computers are completely dependent on humans for interpretation).
What aspects of the trend haven’t happened yet?
Borders have been broken down that previously restrained us. The Internet and Hyptertext are enabling connectivity with humans and interoperability for computer systems that store information. Computers in turn, are enabling humans to process tasks that could not be done before. If the longer term trend is connecting and bridging systems, then the demon to be demolished are the borders that create division.
So with that in mind, we can now ask another question: “what borders exist that need to be broken down?” What it all comes down to is “access”. Or more specifically, access to data, access to connectivity, and access to computing. Which brings us back to the word ubiquity: we now need to strive to bridge the gap in those three domains and make them omnipresent. Information accessible from anywhere, by anyone.
Let’s now look at this in a bit more detail
– Ubiquitous data: We need a world where data can travel without borders. We need to unlock all the data in our world, and have it accessible by all where possible. Connecting data is how we create information: the more data at our hands, the more information we can generate. Data needs to break free – detached from the published form and atomised for reuse.
– Ubiquitous connectivity: If the Internet is a global network that connects the world, we need to ensure we can connect to that network irregardless of where we are. The value of our interconnected world can only achieve its optimum if we can connect wherever with whatever. At home on your laptop, at work on your desktop, on the streets with your mobile phone. No matter where you are, you should be able to connect to the Internet.
– Ubiquitous computing: Computers need to become a direct tool available for our mind to use. They need to become an extension of ourselves, as a “sixth sense”. The border that prevents this, is the non-assimilation of computing into our lives (and bodies!). Information processing needs to become thoroughly integrated into everyday objects and activities.
Examples of when we have ubiquity
My good friend Andrew Aho over the weekend showed me something that he bought at the local office supplies shop. It was a special pen that, well, did everything.
– He wrote something on paper, and then through his USB, could transfer an exact replica to his computer in his original handwriting.
– He could perform a search on his computer to find a word in his digitised handwritten notes
– He was able to pass the pen over a pre-written bit of text, and it would replay the sounds in the room when he wrote that word (as in the position on the paper, not the time sequence)
– Passing the pen over the word also allowed it to be translated into several other languages
– He could punch out a query with the drawn out calculator, to compute a function
– and a lot more. The company has now created an open API on top of its platform – meaning anyone can now create additional features that build on this technology. It has the equivalent opportunity to when the Web was created as a platform, and anyone was allowed to build on top of it.
The pen wasn’t all that bulky, and it did this simply by having a camera attached, a microphone and special dotted paper that allowed the pen to recognise its position. Imagine if this pen could connect to the Internet, with access to any data, and the cloud computing resources for more advanced queries?
Now watch this TED video to the end, which shows the power when we allow computers to be our sixth sense. Let your imagination run wild as you watch it – and while it does, just think about ubiquitous data, connectivity, and computation which are the pillars for such a future.
Trends right now enabling ubiquity
So from the 10,000 feet view that I’ve just shown you, let’s now zoom down and look at trends occurring right now. Trends that are heading towards this ever growing force towards ubiquity.
From the data standpoint, and where I believe this next wave of innovation will centre on, we need to see two things: Syntactic Interoperability and Semantic Interoperability. Syntactic interoperability is when two or more systems can communicate with each other – so for example, having Facebook being able to communicate with MySpace (say, with people sending messages to each other). Semantic interoperability is the ability to automatically interpret the information exchanged meaningingfully – so when I Google Paris Hilton, the search engine understands that I want a hotel in a city in Europe, not a celebrity.
The Semantic Web and Linked Data is one key trend that is enabling this. It’s interlinking all the information out there, in a way that makes it accessible for humans and machines alike to reuse. Data portability is similarly another trend (of which I try to focus my efforts), where the industry is fast moving to enable us to move our identities, media and other meta data wherever we want to.
…the whole point of working on open building blocks for the social web is much bigger than just creating more social networks: our challenge is to build technologies that enhance the network and serve people so that they in turn can go and contribute to building better and richer societies…I can think of few other endeavors that might result in more lasting and widespread benefits than making the raw materials of human connection and knowledge sharing a basic and fundamental property of the web.
The DiSo Project that Chris leads is an umbrella effort that is spearheading a series of technologies, that will lay the infrastructure for when social networking will become “like air“, as Charlene Li has been saying for the last two years.
One of the most popular open source pieces of software (Drupal) has now for a while been innovating on the data side rather than on other features. More recently, we’ve seen Google announce it will cater better for websites that markup in more structured formats, giving an economic incentive for people to participate in the Semantic Web. API‘s (ways for external entities to access a website’s data and technology) are now flourishing, and are providing a new basis for companies to innovate and allow mashups (like newspapers).
As for computing and connectivity, these are more hardware issues, which will see innovation at a different pace and scale to the data domain. Cloud computing has long been understood as a long term shift, and which aligns with the move to ubiquitous computing. Theoretically, all you will need is an Internet connection, and with the cloud, be able to have computing resources at your disposal.
On the connectivity side, we are seeing governments around the world make broadband access a top priority (like the Australian governments recent proposal to create a national broadband network unlike anything else in the world). The more evident trend in this area however, will be the mobile phone – which since the iPhone, has completely transformed our perception of what we can done with this portable computing device. The mobile phone, when connected to the cloud carrying all that data, unleashes the power that is ubiquity.
And then?
Along this journey, we are going to see some unintended impacts, like how we are currently seeing social media replacing the need for a mass media. Spin-off trends will occur which any reasonable person will not be able to predict, and externalities (both positive and negative) will emerge as we drive towards this longer term trend of everything and everyone being connected. (The latest, for example, being the real time web and the social distribution network powering it).
It’s going to challenge conventions in our society and the way we go about our lives – and that’s something that we can’t predict but just expect. For now, however, the trend is pointing to how do we get ubiquity. Once we reach that, then we can ask the question of what happens after it – that being: what happens when everything is connected. But until then, we’ve got to work out on how do we get everything connected in the first place.
Hi - my name is Elias Bizannes, tweetfully known as @EliasBiz where I tend to post more. I've been blessed with not just one but two unpronounceable names: I pronounce them as E-lee-uh(s) bi-ZAH-nis